
- home
首页
links
-
view_list分类keyboard_arrow_down
-
access_time归档keyboard_arrow_down
-
view_carousel页面keyboard_arrow_down
rss_feed
友人帐
RSS订阅
请注意,本文编写于 1491 天前,最后修改于 1491 天前,其中某些信息可能已经过时。
这一道题的主要考点是Base58编码方式的识别与brainfuck语言解释器。理论上来说,这道题可以算是一道经验题吧,感觉识别了题目后,后续工作还是比较简单的。但是由于是C++的源码,对于有用的代码识别还是有很大的困难的。主要是我的代码看的还是太少了,对于主要的循环不敏感。当时比赛的时候自己把这道题当作算法题去处理,一行一行分析代码,最后导致心力憔悴的放弃了。C++逆向题的一大特点可能就是看起来很复杂,很多库函数和调用将代码搞得乱七八糟的。以后还是要多加练习这一方面的题目,毕竟动态调试你又不熟悉,纯静态分析题你又看不懂,那不就是团队毒瘤嘛。ヽ(*。>Д<)o゜仔细想想发现自己好像现在就是团队毒瘤呢!!
同样的操作,re标准菜鸡操作直接拖入IDA。不要问我为啥不查壳,因为有壳的题目直接放弃(ʅ(´◔౪◔)ʃ)菜鸡从不查壳,除非IDA编译不下去。很好,这道题没有壳,可以放心食用。打开strings,定位到main的主函数,在主函数中发现两个关键函数。两个函数分别是C3A,A56。其中A56为一个主要函数,是一个返回0,1的判断函数。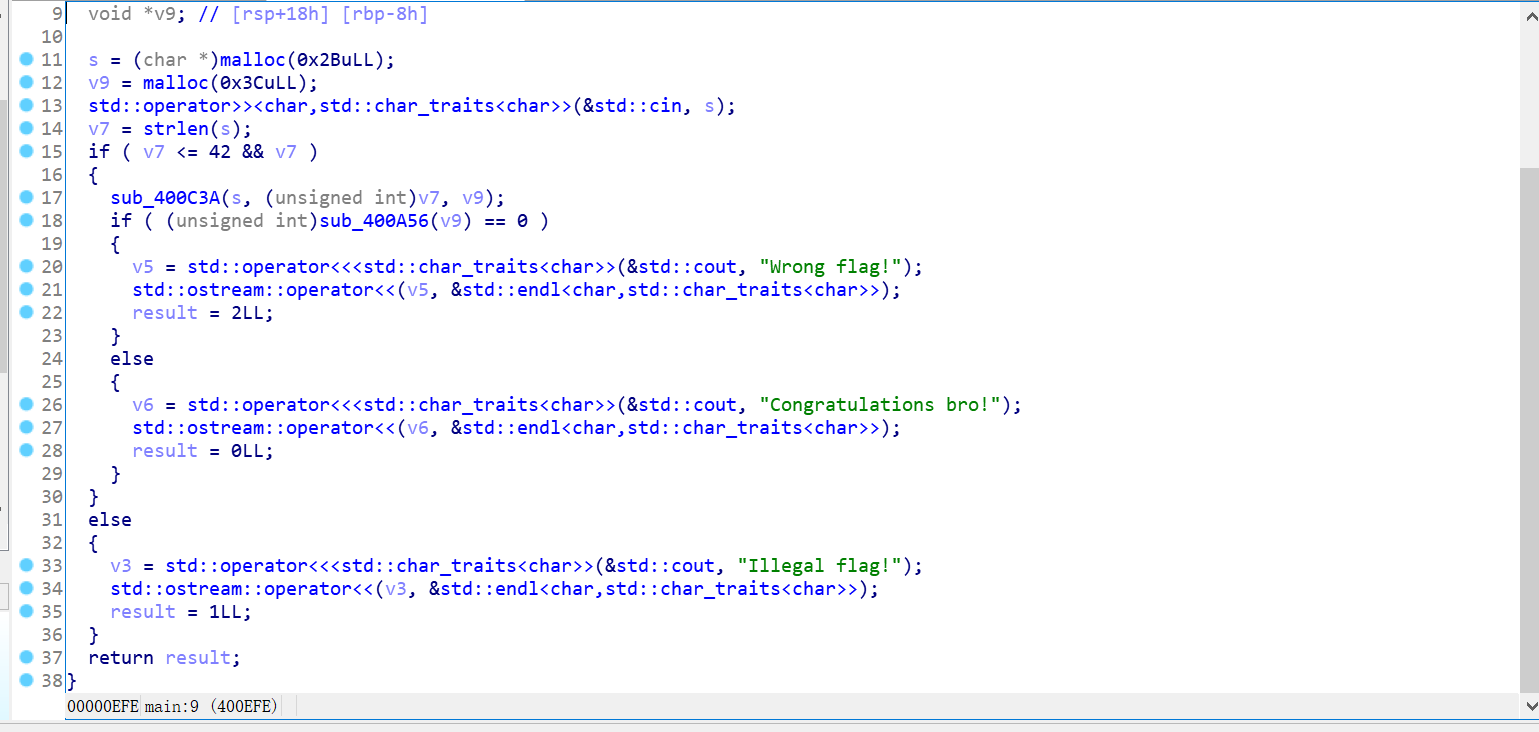
之后我们进入C3A,看看其中的逻辑,看见一个大的循环,里面的算法很像Base58,因为每一个字符都做了58的余,并且在for里面嵌套了一个while的辗转相除算法,所以我们就可以初步认定这是一个base58的加密,即输入的字符串先经过一次base58的加密。
后面还有一个循环,是一个异或循环,我们将里面的数据dump出来,按照加密的方式进行一下还原,发现是一张base58的对照表。也就是说,在输入flag后,进行一次base58的加密,之后进入第二个函数。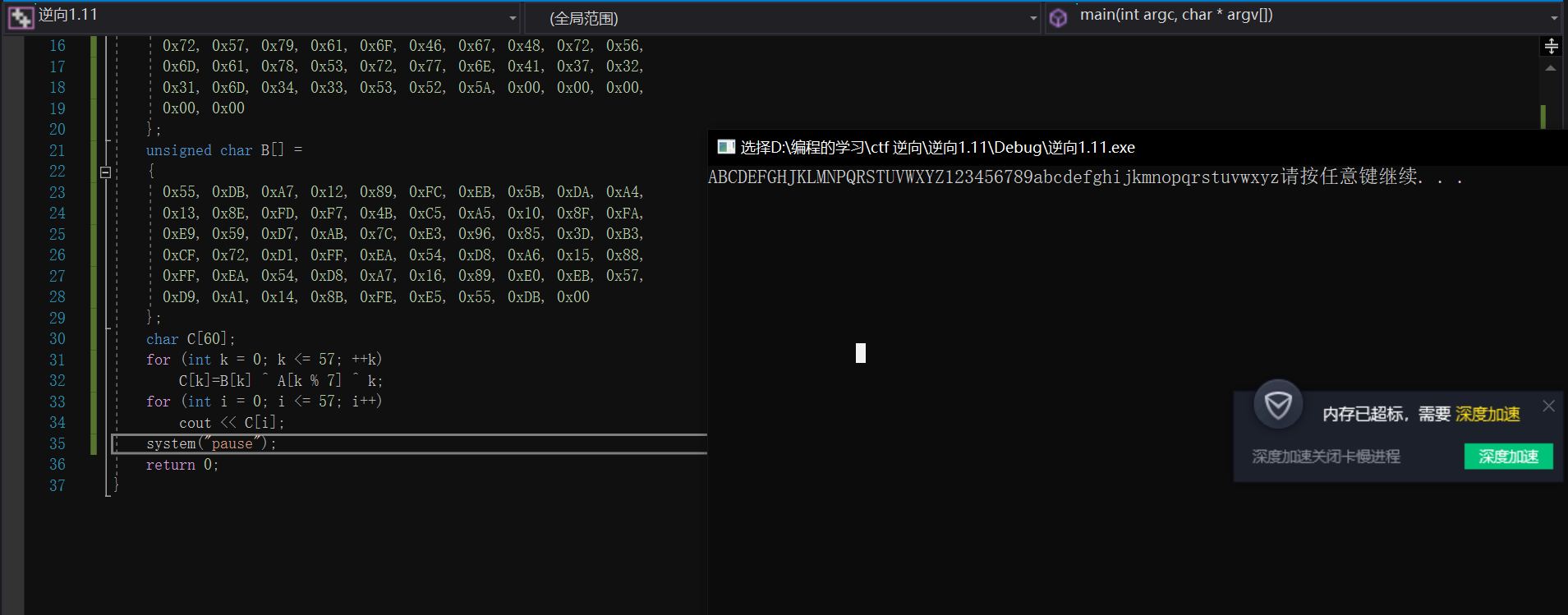
码表:ABCDEFGHJKLMNPQRSTUVWXYZ123456789abcdefghijkmnopqrstuvwxyz
不得不说ctf的比赛提示,你要是知道才可以提示到点子上。比赛的时候我就没想到这个题目是一个提示,以为就是出题人的恶趣味。得,之后一看题解,是真的厉害。奇怪的知识量又增加了。咱们先来介绍一下brainfuck,算是自己学习一下。
Brainfuck是一种极小化的计算机语言,它是由Urban Müller在1993年创建的。由于fuck在英语中是脏话,这种语言有时被称为brainfck或brainf*k,甚至被简称为BF。下面是这八种状态的描述,其中每个状态由一个字符标识:
整个编码就只有几个符号,尽管如此,brainfuck图灵机一样可以完成任何计算任务。虽然brainfuck的计算方式如此与众不同,但它确实能够正确运行。学习完这个编码我的内心也是Fxxk,可能出题人也是这个意思吧。
进入第二个函数,第一个循环统计了一下长度,点进去导出数据。目光转到下面的case函数,在学习过brainfuck后,一眼就能认出来,这是一个brainfuck解释器,用了上面导出的数据,可以在解释器中还原出一段brainfuck代码。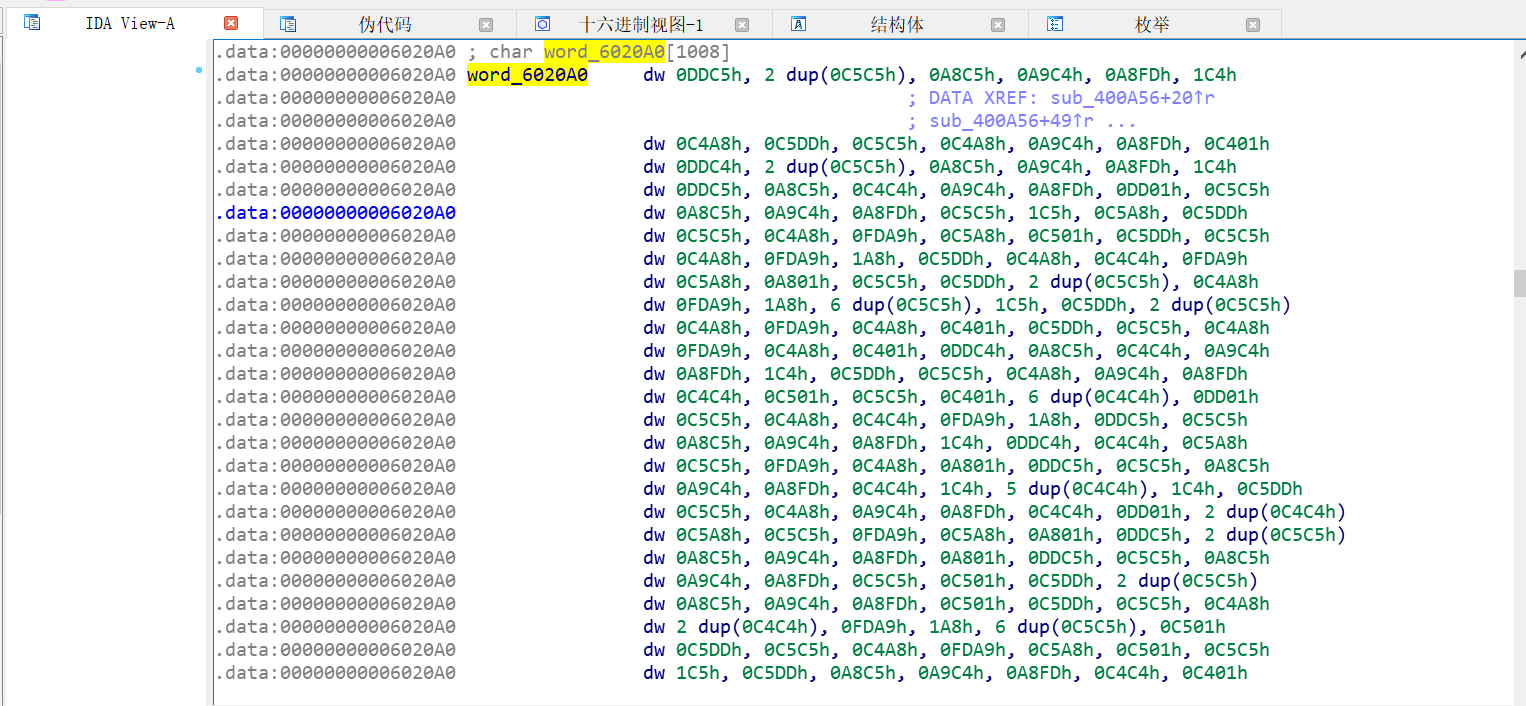
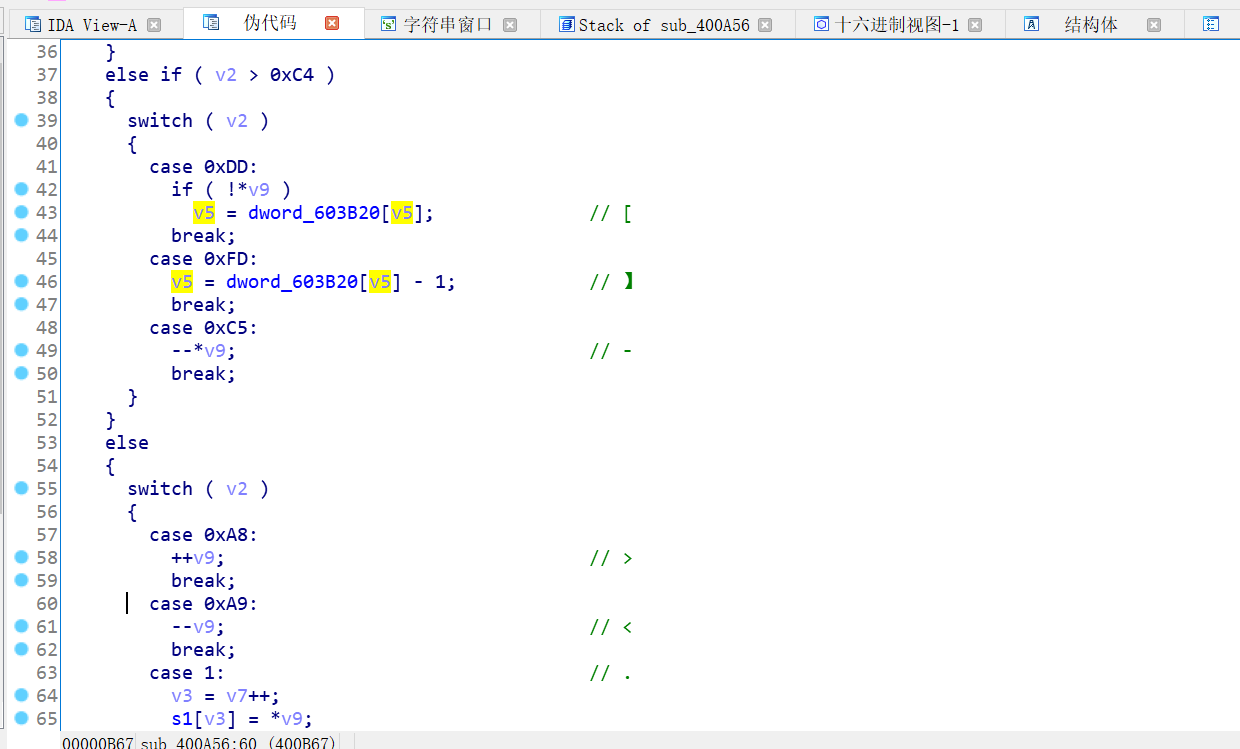
注意看那个指针所做的操作,要是不太能开出来的话就看这个表对比,就会清楚很多。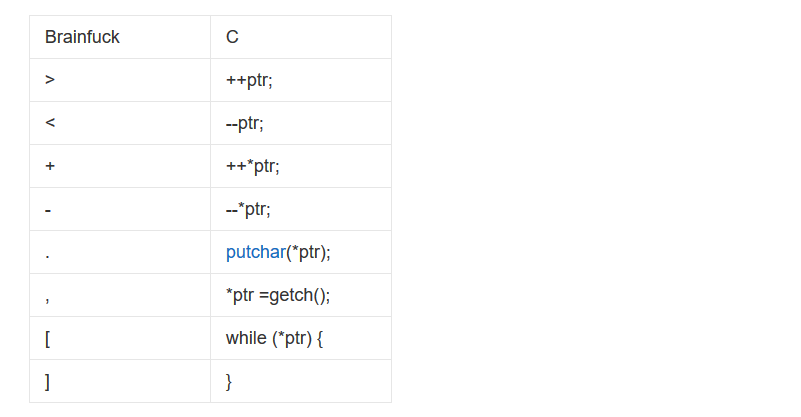
代码进行还原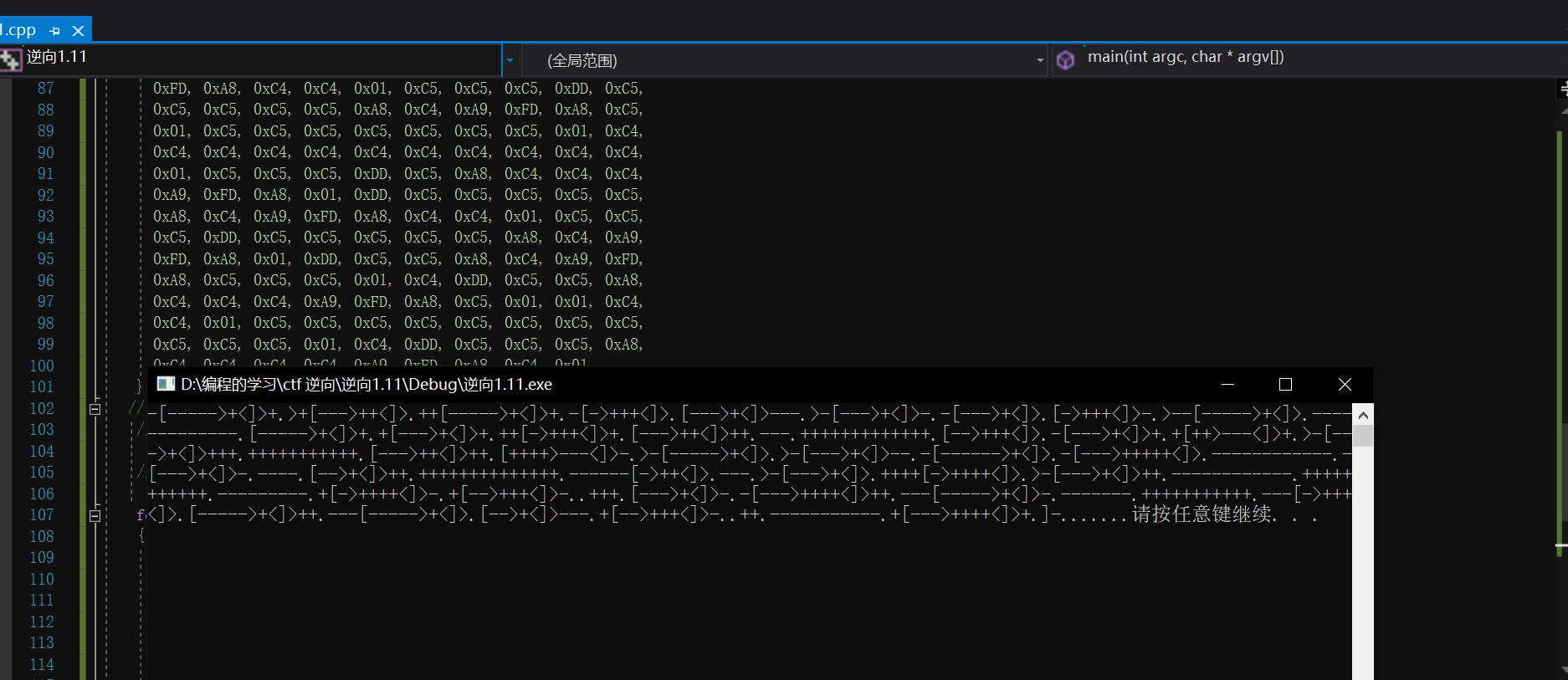
在还原完就已经基本结束了,用在线的解释器还原出加密后的字符串。
还原后字符串:4VyhuTqRfYFnQ85Bcw5XcDr3ScNBjf5CzwUdWKVM7SSVqBrkvYGt7SSUJe
最后再进行base58解密,就得到了flag。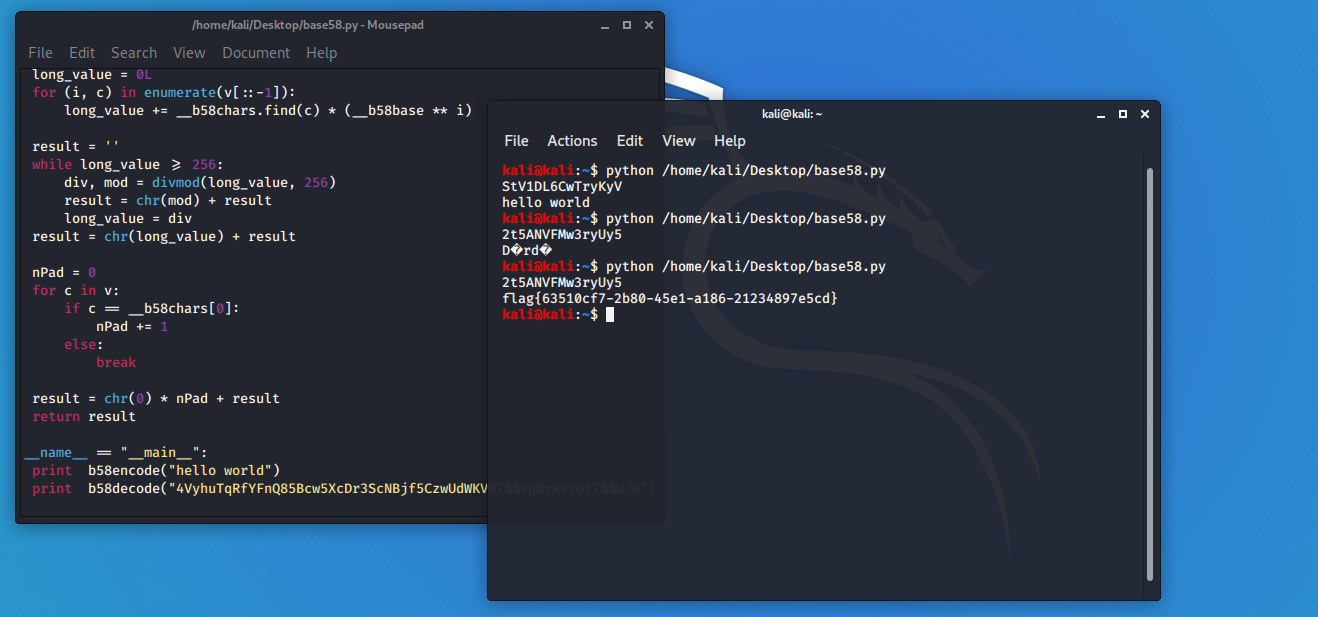
最后再贴上base58还原的脚本(python2)
__b58chars = 'ABCDEFGHJKLMNPQRSTUVWXYZ123456789abcdefghijkmnopqrstuvwxyz'
__b58base = len(__b58chars)
def b58encode(v):
""" encode v, which is a string of bytes, to base58.
"""
long_value = int(v.encode("hex_codec"), 16)
result = ''
while long_value >= __b58base:
div, mod = divmod(long_value, __b58base)
result = __b58chars[mod] + result
long_value = div
result = __b58chars[long_value] + result
# Bitcoin does a little leading-zero-compression:
# leading 0-bytes in the input become leading-1s
nPad = 0
for c in v:
if c == '\0':
nPad += 1
else:
break
return (__b58chars[0] * nPad) + result
def b58decode(v):
""" decode v into a string of len bytes
"""
long_value = 0L
for (i, c) in enumerate(v[::-1]):
long_value += __b58chars.find(c) * (__b58base ** i)
result = ''
while long_value >= 256:
div, mod = divmod(long_value, 256)
result = chr(mod) + result
long_value = div
result = chr(long_value) + result
nPad = 0
for c in v:
if c == __b58chars[0]:
nPad += 1
else:
break
result = chr(0) * nPad + result
return result
if __name__ == "__main__":
print b58decode("4VyhuTqRfYFnQ85Bcw5XcDr3ScNBjf5CzwUdWKVM7SSVqBrkvYGt7SSUJe")
这道题是一道纯静态分析的题目,没有壳,没有动态调试。但是充分的为我们诠释了一个道理,如果知识储备不够达标的话,你可能连提示都看不懂,一道题目的提示如果我们没有用上,我们基本上就只能靠缘分了。只能说继续加油吧!!









































































































全部评论 (暂无评论)
info 还没有任何评论,你来说两句呐!