
- home
首页
links
-
view_list分类keyboard_arrow_down
-
access_time归档keyboard_arrow_down
-
view_carousel页面keyboard_arrow_down
rss_feed
友人帐
RSS订阅
请注意,本文编写于 1451 天前,最后修改于 1451 天前,其中某些信息可能已经过时。
离考试还有一点时间,再加上和队伍混了5月份的Xctf比赛后感觉自己身体被掏空,实在是不想搞一些硬核的东西了。在我在逛我师傅博客的时候,发现最近师傅重启了对赛尔号的数据包逆向的活动(对flash游戏的逆向),虽然最近的成果没有写成博客,但是在动态里面有记录最近的任务的进度。我很好奇(千反田行为),与是就上网了解了一下关于flash游戏的相关知识,但是奈何自己段位实在是太低,发现自己可能无法自行完成这种高级的任务。坐等师傅完成自己的目标,给师傅加油!突然我想起来,曾经好像师傅在博客上ghs,对一个资源网站的拔取实践,但是这个任务不光需要熟练度,而且还需要一些网络协议与爬虫的一些知识。鉴于我小方向是网络安全,所以我研究一下网络爬虫应该不过分吧,不过分吧,吧。
哔哩哔哩最好的学习网站,我找到了一个很新的爬虫教学视频,老师讲得十分的细致,有兴趣的小伙伴可以从这个视频开始。
学习主要任务:
注:主要以笔记的形式呈现,方便自己下次进行查看,b站视频是个很好的资料。
首先解释一下爬虫,爬虫就是用脚本自动的将服务器对网页得反馈进行收集和整理,达到爬取资源的目的。所以我们想要爬取网络资源,我们必须先连上对应的网址,使其产生一个html的反馈,我们在对这个html进行处理。这里就要用到python的urllib模块,由于我使用的使python3.7,所以我们并不用区分urllib和urllib2的区别。
import urllib
from urllib import request
import urllib.parse
import urllib.request
head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'}
req=urllib.request.Request(url="https://www.bilibili.com",headers=head)
res=request.urlopen(req)
##访问百度不会报错,而bilibili则会
#原因是因为服务器只会收到一个单纯的对于该页面访问的请求,但是服务器并不知道发送这个请求使用的浏览器,操作系统,硬件平台等信息,而缺失这些信息的请求往往都是非正常的访问,例如爬虫.
#所以加入Use-Agent可以解决问题(伪装不是爬虫)
#获取一个get请求
print(res.read().decode('utf-8'))
#utf-8进行解码,就是一个网页的html
#获取post请求
#'http:\\httpbin.org '
data=bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")
req=urllib.request.Request(url="http://httpbin.org/post",headers=head,data=data)
ress=request.urlopen(req)
print(ress.read().decode("utf-8"))
#模拟用户真实登陆,注意拼写错误
#超时timeout=1(防止程序卡死)
try:
response=urllib.request.urlopen("http://baidu.com",timeout=0.01)
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
print("time out!")
#response.status 返回网络状态码 404网页无法找到 418发现爬虫
#response.gethearders() 请求头部获取
#response.gethearder("读取单个信息")这是当时自己测试使用的练习脚本,这里有几点是需要注意的,在测试的初期,首先是测试百度,由于百度没有检测或者说不关心你的请求头部和你的浏览器的类型,所以之接发送请求就可以得到反馈,然而对于其他的一些网站,不允许使用直接urllib直接进行请求的,如果进行异常处理的话,会返回418。所以我们这里要稍微的进行一下Request的包装,User-Agent可以在自己的浏览器任意的一个包中找到,由于请求默认是get请求,所以想要使用post请求的话,我们可以一在封装的时候,封装上data的数据。但是这里要注意的是,data数据要使用二进制流的转化Data=bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")。
这个模块俗称靓汤,可以快速的将一个html或者是其他的模组进行规整化。具体操作已经呈现在代码中了,这里就不进行过多的赘述了。
#-*- codeing=utf-8 -*-
from bs4 import BeautifulSoup
import re
file = open("./test.html","rb")
html = file.read().decode("utf-8")
bs=BeautifulSoup(html,"html.parser")
#print(bs.title)
#print(bs.a)
#print(bs.head)
#获取首个标签
#1.tag 标签里面的内容,默认只找到第一个标签
#print(bs.title.string)
#print(bs.a.attrs)可快速拿到一个标签里面的属性
#2.NavigableString 标签里面的内容(字符串)
#print(bs)
#3.beautifulsoup表示整个文档
#print(bs.a.string)
#4.comment 是一个特殊的 输出的不包含注释符号
#文档的遍历
#print(bs.head.contents)
#print(bs.head.contents[1])
#文档的搜索
#t_list=bs.find_all("link") 搜索标签
#使用正则表达式搜索
#t_list=bs.find_all(re.compile("a"))#莫一个标签和内容
#print(t_list)
#方法:传入一个函数(根据函数搜索)
#def name_is_exists(tag):
# return tag.has_attr("name")
#t_list=bs.find_all(name_is_exists)
#for item in t_list:
# print(item)
#print(t_list)
#2.kwargs 参数
#t_list=bs.find_all(id="head")
#for item in t_list:
# print(item)
#text 参数
#t_list=bs.find_all(text="喜马拉雅")
#t_list=bs.find_all(text=re.compile("\d"))#利用正则表达式查找数字
#for item in t_list:
# print(item)
#css选择器
print(bs.select('id'))#通过标签进行查找
靓汤只能完成关于标签的分类,分完类之后虽然已经基本找到了关键数据,但是由于仍然是html的格式,导致很多的标签与url的link揉在了一起,要想提取关键数据,还得我们的正则表达式。第一次接触的时候是在一篇大佬的题解里面,但是我完全不懂呢。现在学完之后,发现其实自己在数据库里面已经有接触了。这里先放几张图:
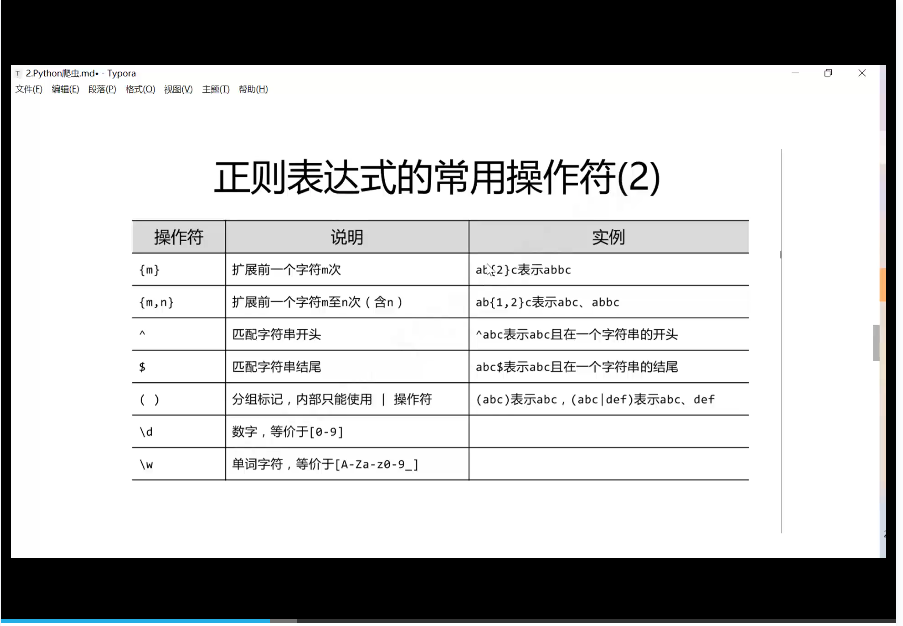
这里是最基本的正则表达式规则,其实只用记住几种最常用的就行了,其他的需要的时候在查询就可以了。
#正则表达式是判断一个字符串的模式 一个文档的格式要求
import re
#创建模式对象
#pat=re.compile("AA")#此处AA是正则表达式
#m=pat.search("ABCAA")#被校验
#print(m)
#<re.Match object; span=(3, 5), match='AA'>
#左闭右开
#m=pat.search("ABCAADDDDDAAAA")#被校验
#print(m)
print(re.findall("[A-Z]","ADSDsdwefwefSDW"))
#['A', 'D', 'S', 'D', 'S', 'D', 'W'] 输出
#sub 替换
print(re.sub("a","A","adadasdasdadadadasadasds"))
#AdAdAsdAsdAdAdAdAsAdAsds
#小提示r"dsad"可以忽略转义字符理论很简单但是用起来真的是十分方便。
由于之前老爹让我帮忙写个喜马拉雅的程序,可以让他下载的音频批量的改名。但是由于我实在没有搞清楚他的加密方式,所以最终失败了。所以对这个破网站有着深深的怨念,所以我就选择这个网站了。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwt
import sqlite3
baseurl="https://www.ximalaya.com/top/free/youshengshu/"
#datalist =getDate(baseurl)
savepath=".\\喜马拉雅.txt"
#saveDate(savepath)
def gatDate(baseurl):
datelist =[]
html=askURL(baseurl)#保存获取到的源码
#爬取网页
#逐一解析数据
soup=BeautifulSoup(html,"html.parser")
list=soup.find_all('script')#5
#print(type(list[5].string))
patname=re.compile(r'"albumTitle":"(.*?)","albumUrl"')
patstory=re.compile(r'"description":"(.*?)","tagStr":')
patset=re.compile(r'"categoryTitle":"(.*?)","lastUpdateTrack":')
albumTitle=re.compile(r'"albumTitle":"(.*?)","albumUrl":')
anchorName=re.compile(r'"anchorName":"(.*?)","lastUptrackAtStr"')
A=patname.findall(list[5].string)
B=patstory.findall(list[5].string)
C=patset.findall(list[5].string)
D=albumTitle.findall(list[5].string)
E=anchorName.findall(list[5].string)
file=open(savepath, mode='w',encoding="utf-8")#这里遇到一个问题,他会检测到第一个非
#print(A[0])
#print(B[0])
#print(C[0])
#print(D[0])
#print(E[0])
#Count=0
for i in range(1,99,1):
H=str(str(i+1)+':'+"名称:"+A[i]+" "+"内容:"+B[i]+" "+"类型:"+C[i]+" "+"副标题:"+D[i]+" "+"作者:"+E[i])
#print(H)
file.write(H)
file.write('\r\n')
#print(str(Count)+": "+item)
#print(H)
#saveData(H)
file.close()
#m=pat.findall(list[5].string)
#print(n)
#A=list[5].string
#print(A[458:462])
#list2=list.find_all('script')
#print(list2)
#return datalist
#def saveData(string):
# file=open(savepath, mode='+',encoding="utf-8")
# file.write(string)
# file.close()
# #print("save....")
#保存数据
def askURL(url):
head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'}
#用户代理伪装(什么水平的前端网页可以显示)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
if __name__=="__main__":
#调用函数,当程序执行时程序的入口
#main()
#askURL("https://www.ximalaya.com/top/free/youshengshu/")
gatDate(baseurl)完成收工,这次主要是为下一次上网ghs做一下理论储备。









































































































全部评论 (共 4 条评论)