
- home
首页
links
-
view_list分类keyboard_arrow_down
-
access_time归档keyboard_arrow_down
-
view_carousel页面keyboard_arrow_down
rss_feed
友人帐
RSS订阅
请注意,本文编写于 556 天前,最后修改于 556 天前,其中某些信息可能已经过时。
这两天在逛小蓝鸟的时候,有一个我关注的博主分享了一个关于zip的有趣小知识。在我们使用zip对目录和文件进行压缩的时候,如果采用先打包,后压缩的策略生成的压缩包会比直接采用压缩的策略所生成的压缩包大小更小。博主也解释了其中的原因。我对于这个现象很好奇, 想着不妨自己试一试,系统的探究一下整个zip压缩算法的原理。心动不如行动,于是就有了这篇文章。
首先我尝试复现了博主所说的这一现象,我使用了曾经CTF的一个文件夹里面包含两个可执行文件和一个文本文件,在压缩后进行对比,我发现压缩包的大小确实缩小了。很有趣的现象!0@0
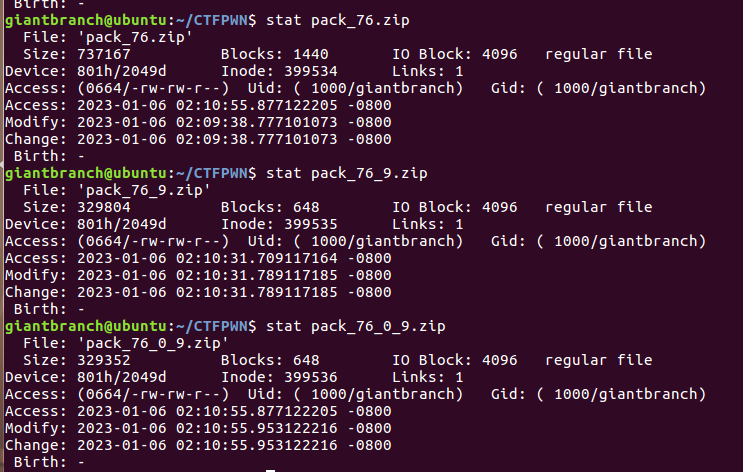
我们发现源文件大小是737167B,采用策略一生成的zip大小为329352B,采用策略二生成的zip大小为329804B,大小大概缩小了500B左右。
对于计算机数据而言,一般会存在两种类型的重复。
zip算法主要就是对这两种形式的重复进行压缩,压缩过程整体观感很像数据结构与算法中的对图片像素算法压缩的过程。(实际上PNG格式的图片就是一种压缩后的图片格式)。
短语形式的重复,即三个字节以上的重复,对于这种重复,zip用两个数字:第一个数字用来表示重复位置距当前压缩位置的距离。第二个数字用来表示重复的长度,来表示这个重复。
单字节的重复,一个字节只有种可能的取值,某些字节出现次数可能较多,另一些则较少,在统计上有分布不均匀的倾向,给种字节取值重新编码,以达到压缩的目的。(哈夫曼树编码)
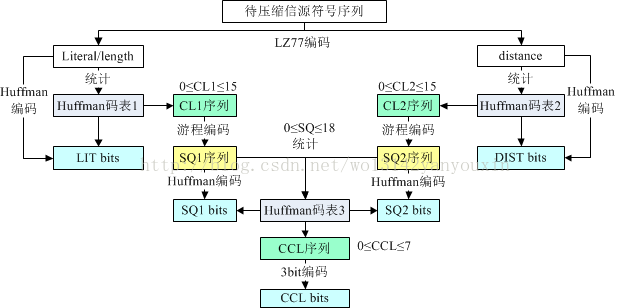
在一般情况下,是首先进行短语形式重复的压缩,然后再进行单字节重复压缩。由于单字节的重复压缩方法是我们所熟知的哈夫曼树编码,这里就不再赘述了。这里主要手动模拟一下短语形式的重复。
这里使用wo13142yanyouxin师傅的所用的例子,原博客地址。
一个非常金典的例子来说明:生,容易。活,容易。生活,不容易。所谓LZ压缩就是当扫描到了某一个数据是,回过头来看前面扫描的数据中有没有出现这个数据,如果出现了就用这个数据与前面出现的数据的距离distance和重复的字符数长度lenght来表示,而没有重复的数据用literal表示。
根据上图,滑动窗口的大小决定着压缩的程度,越大压缩的越严重,但是滑动窗口的大小越大,压缩的速度也就越慢,在速度和压缩程度上我们合理分配权重,最后取32KB是最合适的。
在进行完短语形式的重复压缩算法后我们会生出distance,lenght/literal几个数据项,这是我们会使用哈夫曼树的方法对其进行压缩,使其压缩率更高。考虑压缩效率的原因,我们把 distance等数据根据数量划分成30个区间,每一个区间所使用的位数也有所不同。
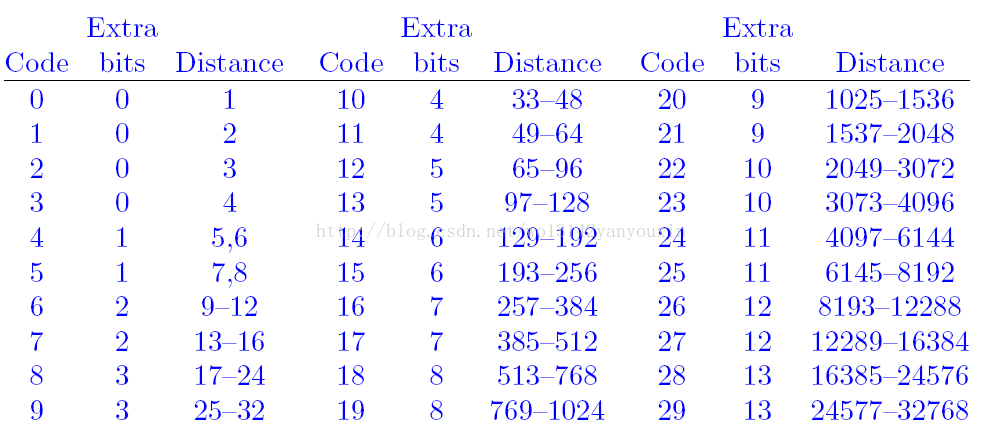
按照上面的方法,LZ的编码结果就变成四块:CL1、CL2、LIT比特流、DIST比特流。CL1、CL2是码字长度的序列。会形成整数组成的码表,此码表可以再次进行单字节压缩。
对码表采用二次压缩时,遵循游程的概念进行压缩。举例:
4, 4, 4, 4, 4, 3, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2
游程编码的结果为:4, 16, 01(二进制), 3, 3, 3, 6, 16, 11(二进制), 16, 00(二进制), 17,011(二进制), 2, 16, 00(二进制)这里的游程概念与密码学中的游程概念是一致的,就本例子而言,4的游程为5,3的游程为3,6的游程为10,0的游程为6,2的游程为4。这里的的压缩格式是4后面还有几个4(即游程数-1),其中在压缩过程中游程小于4的不进行压缩,后续两位二进制位表示的分别为:00-->3,01-->4,10-->5,11-->6。16则为一般数字的标志位,出现后则表示这里进行了压缩,0在数据中经常出现,所以使用特殊的17,18进行压缩表示,后边的游程也采用更多的bit位进行表示(17,011(二进制)表示连续出现6个0;18,0111110(二进制)表示连续出现62个0。)。
本节将以打包文件和压缩率最高的的zip进行对比,在对比的过程中对zip文件头进行分析。本节的顺序是笔者提出一些问题,顺着问题继续思考,所以可能因为思维的跳跃导致逻辑混乱。
以我的想法,我认为打包文件会因为多出zip文件头,导致其尺寸大于原有目录文件尺寸。但是经过实践我发现,三种不同的查询方法,居然出现了2种不同的结果。
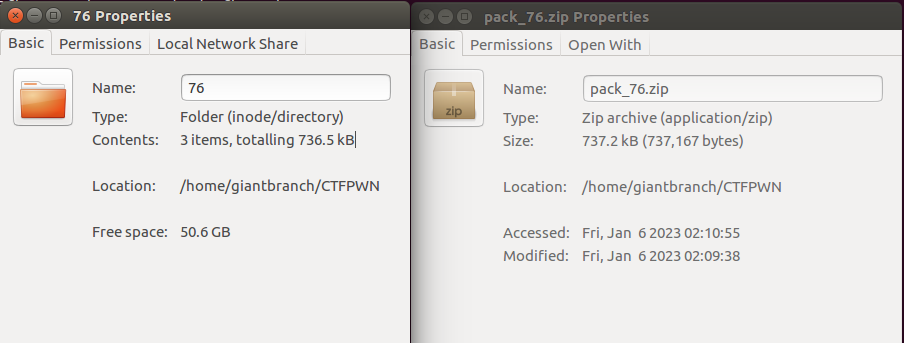
这种情况下,76目录的大小为736.5KB,zip打包文件大小为737.2KB。在这种情况下目录大小比打包文件大0.7KB。
而在ls与du的形况下,结果是相反的,在du的情况下,76的目录是732K,zip的打包文件720K。
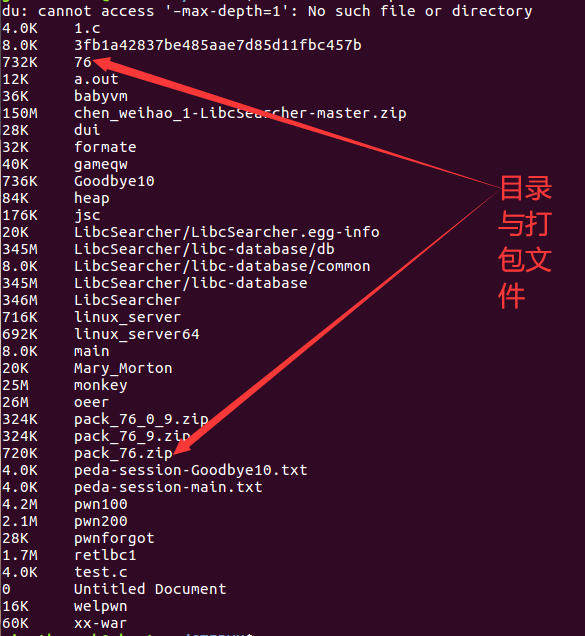
在ls中,76的目录大小728K,打包大小为720K,也是目录的大小会大于打包的大小。

在这种情况下,我准备看一下zip指令的源码文件。
whereis zip
dpkg -S /usr/bin/zip
sudo apt-get source zip既可以将zip的源码下载到当前目录。
下方是zip源码和打包方式部分代码定义的节选部分。在代码初始部分,代码定义了一个options的结构体,其中我们找到了关于压缩0~9的相关定义。(PS:#ifdef是条件编译选项,目的是为了兼容各类系统)
struct option_struct far options[] = {
/* short longopt value_type negatable ID name */
#ifdef EBCDIC
{"a", "ascii", o_NO_VALUE, o_NOT_NEGATABLE, 'a', "to ascii"},
#endif /* EBCDIC */
#ifdef CMS_MVS
{"B", "binary", o_NO_VALUE, o_NOT_NEGATABLE, 'B', "binary"},
#endif /* CMS_MVS */
#ifdef TANDEM
{"B", "", o_NUMBER_VALUE, o_NOT_NEGATABLE, 'B', "nsk"},
#endif
{"0", "store", o_NO_VALUE, o_NOT_NEGATABLE, '0', "store"},
{"1", "compress-1", o_NO_VALUE, o_NOT_NEGATABLE, '1', "compress 1"},
{"2", "compress-2", o_NO_VALUE, o_NOT_NEGATABLE, '2', "compress 2"},
{"3", "compress-3", o_NO_VALUE, o_NOT_NEGATABLE, '3', "compress 3"},
{"4", "compress-4", o_NO_VALUE, o_NOT_NEGATABLE, '4', "compress 4"},
{"5", "compress-5", o_NO_VALUE, o_NOT_NEGATABLE, '5', "compress 5"},
{"6", "compress-6", o_NO_VALUE, o_NOT_NEGATABLE, '6', "compress 6"},
{"7", "compress-7", o_NO_VALUE, o_NOT_NEGATABLE, '7', "compress 7"},
{"8", "compress-8", o_NO_VALUE, o_NOT_NEGATABLE, '8', "compress 8"},
{"9", "compress-9", o_NO_VALUE, o_NOT_NEGATABLE, '9', "compress 9"},
{"A", "adjust-sfx", o_NO_VALUE, o_NOT_NEGATABLE, 'A', "adjust self extractor offsets"},在主函数处我们找到了输入参数处理函数,其中如果参数为0时,设置method变量为打包,level=0,其余的1~9则设置level选项为对应的数值。所以method与level两个参数应该为我们接下去定位主体函数的线索。
case '0':
method = STORE; level = 0; break;
case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
/* Set the compression efficacy */
level = (int)option - '0'; break;
case 'A': /* Adjust unzipsfx'd zipfile: adjust offsets only */
adjust = 1; break;在globals.c的全局变量默认定义中,我们发现,若果不指定level参数,zip文件将默认执行参数为6的压缩方式。
int recurse = 0; /* 1=recurse into directories encountered */
int dispose = 0; /* 1=remove files after put in zip file */
int pathput = 1; /* 1=store path with name */
#ifdef RISCOS
int scanimage = 1; /* 1=scan through image files */
#endif
int method = BEST; /* one of BEST, DEFLATE (only), or STORE (only) */
int dosify = 0; /* 1=make new entries look like MSDOS */
int verbose = 0; /* 1=report oddities in zip file structure */
int fix = 0; /* 1=fix the zip file, 2=FF, 3=ZipNote */
int filesync = 0; /* 1=file sync, delete entries not on file system */
int adjust = 0; /* 1=adjust offsets for sfx'd file (keep preamble) */
int level = 6; /* 0=fastest compression, 9=best compression */
int translate_eol = 0; /* Translate end-of-line LF -> CR LF */随后我们在zipup.c中找到了初始压缩代码。定位到lm_init函数,在此函数中第一个参数调用了leve参数。
#else /* !USE_ZLIB */
/* Set the defaults for file compression. */
read_buf = file_read;
/* Initialize deflate's internals and execute file compression. */
bi_init(file_outbuf, sizeof(file_outbuf), TRUE);
ct_init(&z_entry->att, cmpr_method);
lm_init(level, &z_entry->flg);
return deflate();
#endif /* ?USE_ZLIB */lm_init中除了一开始判断pack_level时用到了level参数,在后续中max_lazy_match,good_match,max_chain_length三个参数中调用了configuration_table(配置表选项)。所以我们将目光转移至configuration_table配置表。
void lm_init (pack_level, flags)
int pack_level; /* 0: store, 1: best speed, 9: best compression */
ush *flags; /* general purpose bit flag */
{
register unsigned j;
if (pack_level < 1 || pack_level > 9) error("bad pack level");
/* Do not slide the window if the whole input is already in memory
* (window_size > 0)
*/
sliding = 0;
if (window_size == 0L) {
sliding = 1;
window_size = (ulg)2L*WSIZE;
}
/* Use dynamic allocation if compiler does not like big static arrays: */
#ifdef DYN_ALLOC
if (window == NULL) {
window = (uch far *) zcalloc(WSIZE, 2*sizeof(uch));
if (window == NULL) ziperr(ZE_MEM, "window allocation");
}
if (prev == NULL) {
prev = (Pos far *) zcalloc(WSIZE, sizeof(Pos));
head = (Pos far *) zcalloc(HASH_SIZE, sizeof(Pos));
if (prev == NULL || head == NULL) {
ziperr(ZE_MEM, "hash table allocation");
}
}
#endif /* DYN_ALLOC */
/* Initialize the hash table (avoiding 64K overflow for 16 bit systems).
* prev[] will be initialized on the fly.
*/
head[HASH_SIZE-1] = NIL;
memset((char*)head, NIL, (unsigned)(HASH_SIZE-1)*sizeof(*head));
/* Set the default configuration parameters:
*/
max_lazy_match = configuration_table[pack_level].max_lazy;
good_match = configuration_table[pack_level].good_length;
#ifndef FULL_SEARCH
nice_match = configuration_table[pack_level].nice_length;
#endif
max_chain_length = configuration_table[pack_level].max_chain;
if (pack_level <= 2) {
*flags |= FAST;
} else if (pack_level >= 8) {
*flags |= SLOW;
}
/* ??? reduce max_chain_length for binary files */
strstart = 0;
block_start = 0L;
#if defined(ASMV) && !defined(RISCOS)
match_init(); /* initialize the asm code */
#endif
j = WSIZE;
#ifndef MAXSEG_64K
if (sizeof(int) > 2) j <<= 1; /* Can read 64K in one step */
#endif
lookahead = (*read_buf)((char*)window, j);
if (lookahead == 0 || lookahead == (unsigned)EOF) {
eofile = 1, lookahead = 0;
return;
}
eofile = 0;
/* Make sure that we always have enough lookahead. This is important
* if input comes from a device such as a tty.
*/
if (lookahead < MIN_LOOKAHEAD) fill_window();
ins_h = 0;
for (j=0; j<MIN_MATCH-1; j++) UPDATE_HASH(ins_h, window[j]);
/* If lookahead < MIN_MATCH, ins_h is garbage, but this is
* not important since only literal bytes will be emitted.
*/
}
值得注意的是,zip文件将0~2定义为快速压缩,3~9定义为慢速压缩。
if (pack_level <= 2) {
*flags |= FAST;
} else if (pack_level >= 8) {
*flags |= SLOW;
}配置表给出的是系列类的参数,并且configuration_table是属于config的一个类。
typedef struct config {
ush good_length; /* reduce lazy search above this match length */
ush max_lazy; /* do not perform lazy search above this match length */
ush nice_length; /* quit search above this match length */
ush max_chain;
} config;
/*减少超过此匹配长度的延迟搜索,不要执行超过此匹配长度的延迟搜索,退出超过此匹配长度的搜索*/
local config configuration_table[10] = {
/* good lazy nice chain */
/* 0 */ {0, 0, 0, 0}, /* store only */
/* 1 */ {4, 4, 8, 4}, /* maximum speed, no lazy matches */
/* 2 */ {4, 5, 16, 8},
/* 3 */ {4, 6, 32, 32},
/* 4 */ {4, 4, 16, 16}, /* lazy matches */
/* 5 */ {8, 16, 32, 32},
/* 6 */ {8, 16, 128, 128},
/* 7 */ {8, 32, 128, 256},
/* 8 */ {32, 128, 258, 1024},
/* 9 */ {32, 258, 258, 4096}}; /* maximum compression */根据注释我们定位到了两个关键函数,void lm_init与ulg deflate (void)两个函数,前者是初始化函数,用于压缩进程的初始化,具体任务是将相应的全局参数进行处理,为压缩初始化进行准备工作。而deflate函数则为压缩过程中的主体函数,负责处理全部压缩流程。deflate_fast则是参数小于3时所调用的函数。
local uzoff_t deflate_fast()
{
IPos hash_head = NIL; /* head of the hash chain */
int flush; /* set if current block must be flushed */
unsigned match_length = 0; /* length of best match */
prev_length = MIN_MATCH-1;
while (lookahead != 0) {
/* Insert the string window[strstart .. strstart+2] in the
* dictionary, and set hash_head to the head of the hash chain:
字典,并将hash_head设置为哈希链的头部
*/
#ifndef DEFL_UNDETERM
if (lookahead >= MIN_MATCH)
#endif
INSERT_STRING(strstart, hash_head);
/* Find the longest match, discarding those <= prev_length.
* At this point we have always match_length < MIN_MATCH
查找最长的匹配,丢弃那些的匹配选项<=prev_length。
此时,我们可以确保 match_length<MIN_match
*/
if (hash_head != NIL && strstart - hash_head <= MAX_DIST) {
/* To simplify the code, we prevent matches with the string
* of window index 0 (in particular we have to avoid a match
* of the string with itself at the start of the input file).
*/
#ifndef HUFFMAN_ONLY
# ifndef DEFL_UNDETERM
/* Do not look for matches beyond the end of the input.
* This is necessary to make deflate deterministic.
*/
if ((unsigned)nice_match > lookahead) nice_match = (int)lookahead;
# endif
match_length = longest_match (hash_head);
/* longest_match() sets match_start */
if (match_length > lookahead) match_length = lookahead;
#endif
}
if (match_length >= MIN_MATCH) {
check_match(strstart, match_start, match_length);
flush = ct_tally(strstart-match_start, match_length - MIN_MATCH);
lookahead -= match_length;
/* Insert new strings in the hash table only if the match length
* is not too large. This saves time but degrades compression.
*/
if (match_length <= max_insert_length
#ifndef DEFL_UNDETERM
&& lookahead >= MIN_MATCH
#endif
) {
match_length--; /* string at strstart already in hash table */
do {
strstart++;
INSERT_STRING(strstart, hash_head);
/* strstart never exceeds WSIZE-MAX_MATCH, so there are
* always MIN_MATCH bytes ahead.
*/
#ifdef DEFL_UNDETERM
/* If lookahead < MIN_MATCH these bytes are garbage,
* but it does not matter since the next lookahead bytes
* will be emitted as literals.
*/
#endif
} while (--match_length != 0);
strstart++;
} else {
strstart += match_length;
match_length = 0;
ins_h = window[strstart];
UPDATE_HASH(ins_h, window[strstart+1]);
#if MIN_MATCH != 3
Call UPDATE_HASH() MIN_MATCH-3 more times
#endif
}
} else {
/* No match, output a literal byte */
Tracevv((stderr,"%c",window[strstart]));
flush = ct_tally (0, window[strstart]);
lookahead--;
strstart++;
}
if (flush) FLUSH_BLOCK(0), block_start = strstart;
/* Make sure that we always have enough lookahead, except
* at the end of the input file. We need MAX_MATCH bytes
* for the next match, plus MIN_MATCH bytes to insert the
* string following the next match.
*/
if (lookahead < MIN_LOOKAHEAD) fill_window();
}
return FLUSH_BLOCK(1); /* eof */
}我们读完代码后发现,当是打包的时候,直接运行如下代码:
strstart += match_length;
match_length = 0;
ins_h = window[strstart];
UPDATE_HASH(ins_h, window[strstart+1]);首先我们先来看一下zip函数下的哈希表的定义方法:lm_init()部分代码
//初始化哈希表
ins_h = 0;
for (j=0; j<MIN_MATCH-1; j++) UPDATE_HASH(ins_h, window[j]);
/* If lookahead < MIN_MATCH, ins_h is garbage, but this is
* not important since only literal bytes will be emitted.
*/zip代码将哈希表初始化成为了两个数组构成,没有使用我们数据结构中常见的链接法或开域法。这里参考了zip压缩算法 源码分析(1),这篇文章的博主做了一张很好看的图片,我们这里借鉴一下。
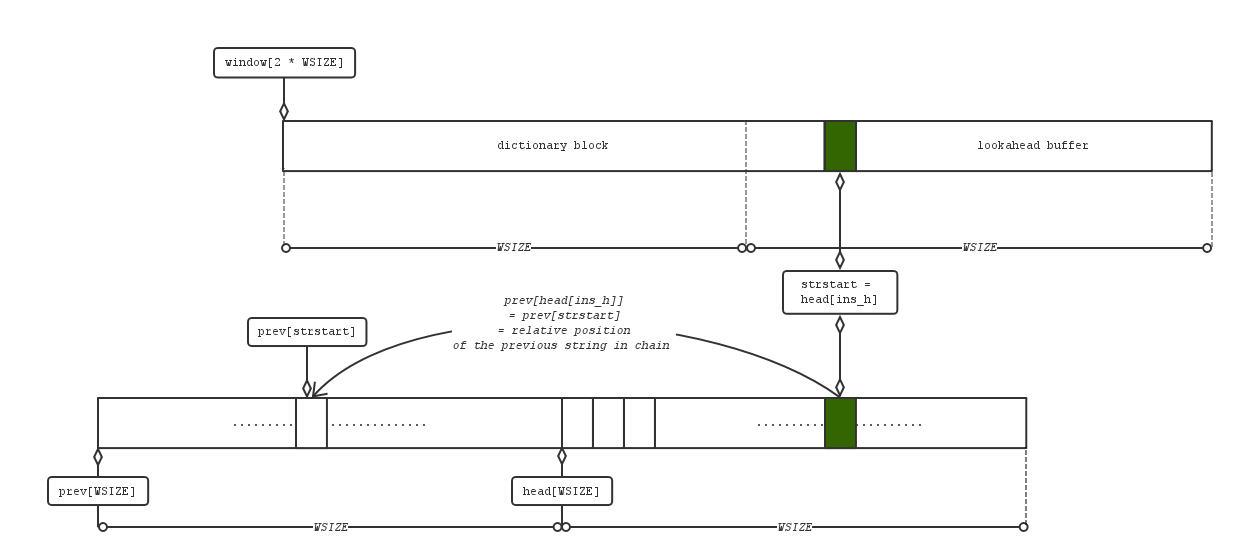
如图,哈希表由2个数组head[WSIZE]与prev[WSIZE]构成,WSIZE = 0x8000 = 32k,
这两个数组构成了许多条链,所有由一个特定哈希函数取到相同哈希码的字符串们组成一条链。
head[]装载所有链头串的地址,prev[]则记录串与串之间的链接关系
之后我们来看一下哈希表的更新函数。
#define HASH_BITS 15
#define MIN_MATCH 3
#define HASH_MASK (HASH_SIZE-1)
//掩码是哈希大小-1,类似于子网掩码由全F构成
#define H_SHIFT ((HASH_BITS+MIN_MATCH-1)/MIN_MATCH)
//确定哈希表位移位数,以默认来算是位移5位
//H_SHIFT 为哈希码长度除以3再向上取整
/*原因摘自zip压缩算法 源码分析(1)emmm我数学功底感人 其实没再明白
设strtsart = s, 此时生成的哈希码只能与window[s], window[s + 1], window[s + 2]有关,这一点是必须的,因此,必须通过左移将之前window[s - i],window[s - i + 1],......,window[s - 1](i >= MIN_MATCH - 1)产生的哈希码去掉,不妨设每次左移r位;
window[s - i]左移一次,window[s - i + 1]左移一次,...,window[s]左移一次,
共有i + 1次机会,从而(i + 1) * r >= HASH_BITS, 且 i >= MIN_MATCH - 1,
于是 r = (HASH_BITS + i) / (i + 1) <= (HASH_BITS + MIN_MATCH - 1) / MIN_MATCH
*/
#define UPDATE_HASH(h,c) (h = (((h)<<H_SHIFT) ^ (c)) & HASH_MASK)
//更新哈希表,将(h-5)位与c进行异或作为新的哈希h值
#define INSERT_STRING(s, match_head) \
(UPDATE_HASH(ins_h, window[(s) + MIN_MATCH-1]), \
prev[(s) & WMASK] = match_head = head[ins_h], \
head[ins_h] = (s))
//prev[(字符c的位置s) & WMASK] = 同一链中位于c之前那个串在窗口中的起始字符位head[(以c为首的串生成的哈希码ins_h)] = c在窗口中的位置综上所述,zip的打包操作后,为了可以实现随机访问,为文件创建了哈希表,我们可以看见在代码运行过程中,当参数时0时,并没有任何的压缩操作。但是为所有文件创建了哈希表,并且也会有文件头。我们发现就算zip程序不对文件进行处理,也会初始化一个哈希表,它会使用UPDATE_HASH把你所有的零散的文件进行链接。
但是我还是不是很确定,我只是猜测这里打包可能会稍微的大一点。(这个问题留在下一个Q中解决,因为zip文件头中也存有压缩包信息)
一个ZIP文件大致可以分为三个部分:数据存储区(File Entry)和中心目录区(Central Directory)以及一个目录结束标识(End of central directory record)组成。
如果有多个文件则会在数据存储区中找到多个{文件头+文件数据+数据描述符}的数据结构。
我们先来看一下zip的头部数据,然后再来研究不同的压缩方式所带来的数据存储区之间的关系。
Overall .ZIP file format:
[local file header 1]
[file data 1]
[data descriptor 1]
.
.
.
[local file header n]
[file data n]
[data descriptor n]
[archive decryption header] (EFS)
[archive extra data record] (EFS)
[central directory]
[zip64 end of central directory record]
[zip64 end of central directory locator]
[end of central directory record]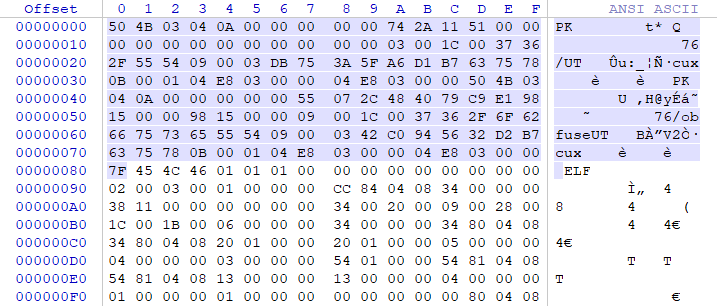
| Offset | Bytes | Contents | Descriptor |
|---|---|---|---|
| LOCAL FILE HEADER | |||
| 00000000 | 4 | 50 4B 03 04 | 文件头标识(0x04034b50) |
| 00000004 | 2 | 0A 00 | 解压文件所需 pkware最低版本 |
| 00000006 | 2 | 00 00 | 通用比特标志位 |
| 00000008 | 2 | 00 00 | 压缩方式 打包 |
| 0000000A | 2 | 74 2A | 文件最后修改时间 |
| 0000000C | 2 | 11 51 | 文件最后修改日期 |
| 0000000E | 4 | 00 00 00 00 | crc-32校验码 |
| 00000012 | 4 | 00 00 00 00 | 压缩后的大小 |
| 00000016 | 4 | 00 00 00 00 | 未压缩的大小 |
| 0000001A | 2 | 03 00 | 0x0003 文件名长度 |
| 0000001C | 2 | 00 50 | 扩展区长度0x5000 |
| 0000001E | 3 | 37 36 | 文件名 76 |
| FILE DATA | |||
| 00000020 |
下取自官方文档,只有当通用bit位第3位设置有效的时候,才会出现Data descriptor字段,所以在第一部分没有文件描述,紧接着就是第二个打包文件PK。第一个压缩文件应该为目录文件,第二个为一个ELF文件,所以我们这里看两个文件头。
C. Data descriptor:
crc-32 4 bytes
compressed size 4 bytes
uncompressed size 4 bytes
This descriptor exists only if bit 3 of the general
purpose bit flag is set (see below). It is byte aligned
and immediately follows the last byte of compressed data.
This descriptor is used only when it was not possible to
seek in the output .ZIP file, e.g., when the output .ZIP file
was standard output or a non seekable device. For Zip64 format
archives, the compressed and uncompressed sizes are 8 bytes each.对于第二个文件头,我们有如下文件提示。
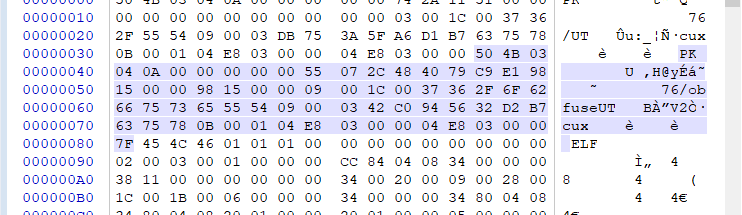
| Offset | Bytes | Contents | Descriptor |
|---|---|---|---|
| LOCAL FILE HEADER | |||
| 0000003D | 4 | 50 4B 03 04 | 文件头标识(0x04034b50) |
| 00000041 | 2 | 0A 00 | 解压文件所需 pkware最低版本 |
| 00000043 | 2 | 00 00 | 通用比特标志位 |
| 00000045 | 2 | 00 00 | 压缩方式 打包 |
| 00000047 | 2 | 55 07 | 文件最后修改时间 |
| 00000049 | 2 | 2c 48 | 文件最后修改日期 |
| 0000004B | 4 | 40 79 C9 E1 | crc-32校验码 |
| 0000004F | 4 | 98 15 00 00 | 压缩后的大小 |
| 00000053 | 4 | 98 15 00 00 | 未压缩的大小 |
| 00000057 | 2 | 09 00 | 0x0009 文件名长度 |
| 00000059 | 2 | 1c 00 | 扩展区长度0x5000 |
| 0000005B | 9 | 37 36 2F 6f 62 66 75 73 65 | 文件名 76/obfuse |
核心目录也是将压缩包中的所有的文件头顺序排列,我们这里看一个。
F. Central directory structure:
[file header 1]
.
.
.
[file header n]
[digital signature] 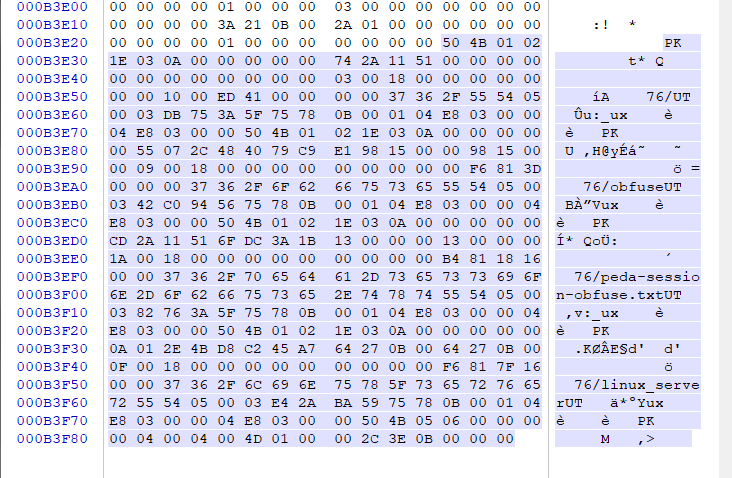
| Offset | Bytes | Contents | Descriptor |
|---|---|---|---|
| 000B3E2C | 4 | 50 4B 01 02 | 核心目录文件header标0x02014b50 |
| 000B3E30 | 2 | 1E 03 | 压缩所用的pkware版本 |
| 000B3E32 | 2 | 0A 00 | 解压所需pkware的最低版本 |
| 000B3E34 | 2 | 00 00 | 通用位标记 |
| 000B3E36 | 2 | 00 00 | 压缩方法 |
| 000B3E38 | 2 | 74 2A | 文件最后修改时间 |
| 000B3E3A | 2 | 11 51 | 文件最后修改日期 |
| 000B3E3C | 4 | 00 00 00 00 | crc-32校验码 |
| 000B3E40 | 4 | 00 00 00 00 | 压缩后的大小 |
| 000B3E44 | 4 | 00 00 00 00 | 未压缩的大小 |
| 000B3E48 | 2 | 03 00 | 文件名长度 |
| 000B3E4A | 2 | 18 00 | 扩展区长度0x0018 |
| 000B3E4C | 2 | 00 00 | 文件注释长度 |
| 000B3E4E | 2 | 00 00 | 文件开始位置的磁盘编号 |
| 000B3E50 | 2 | 00 00 | 内部文件属性 |
| 000B3E52 | 4 | 10 00 ED 41 | 外部文件属性 |
| 000B3E56 | 4 | 00 00 00 00 | 本地文件头的相对位移 |
| 000B3E2C | 2 | 37 36 | 目录文件名 |
| 000B3E2C | 扩展域 | ||
| 000B3E2C | 文件注释内容 |
后续几个文件结构与之相似。
| 000B3F79 | 4 | 50 4B 05 06 | 核心目录结束标记(0x06054b50) |
|---|---|---|---|
| 000B3F7D | 2 | 00 00 | 当前磁盘编号 |
| 000B3F7F | 2 | 00 00 | 核心目录开始位置的磁盘编号 |
| 000B3F81 | 2 | 04 00 | 该磁盘上所记录的核心目录数量 |
| 000B3F83 | 2 | 04 00 | 核心目录结构总数 |
| 000B3F85 | 4 | 4D 01 00 00 | 核心目录的大小 |
| 000B3F89 | 4 | 2C 2E 0B 00 | 核心目录开始位置相对于archive开始的位移 |
| 000B3F8D | 2 | 00 00 | 注释长度 |
我们对比压缩包参数为9的参数压缩包与打包文件的头文件与核心目录与核心目录结束段我们可以发现,结构基本没什么太大的变化,也是存在4个核心目录结构每个结构与打包文件相似。所以我们可以知道在单次打包与压缩的过程中,程序会将包括目录在内的所有内容进行分开进行压缩,并为他们建立自己独立的核心目录文件头等。
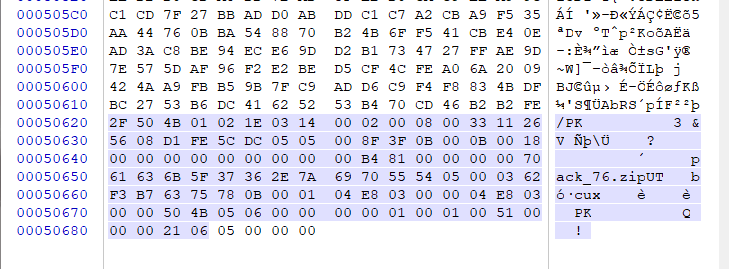
我们可以发现,由于zip文件是一个整体,所以只会存在一个核心目录,这就意味着我们在0x3中看见的算法会对整个zip文件进行压缩。
zip本身会因为实现随机访问会把压缩目录下的每个文件单独压缩,零散文件多了压缩率自然就下来了。两次高质量压缩并不能提升压缩率的原因是,第一次压缩破坏了文件的短语形式重复,第二次压缩的效果就会变差。而先打包一遍就相当于把所有的文件数据链成一块,在压缩时,程序会将zip文件作为一个整体进行压缩,压缩率就会相应地提升,会更有效。
因为打包+压缩的处理方式会添加一些核心目录的信息,而在核心目录中又存在文件名字段。那是否会存在一种可能,核心目录所产生代价远远超过了将文件集体压缩的收益,导致这种压缩策略并不能有效的减少空间?
我们已知linux操作系统中支持的最长文件名为255,我已我们构建一个由空文件组装成的名字长度达到255的目录。
VDCp3aJeQvJbsoGVk0wVtCx4NeeMOV4gmqm6dvJ4AM07ekfOtHTcOZ0FGgGfndazg8YpT8z0com5tAm0aEzXVl2r4wSYux75UGeoGJjuPgEpH95azvD6E63bR2k0KJg8mRLJuYvcr7mDdOE0ln6hCHgg7Bju6mMeLDn4kQc2WCDiW9HJCmf1eqcTW570eUP7RmtWlDUYq3ctPBBQ0ljaoDWagGKfJEloMOVQ3hEPxZGTBYWOuFTp6a8eqizgwCX
wqrIMkeDscPogvNiI4xc2xb4238A821HycJHT2apaJJ5VcOru7Mcc1NpOTFzHO3gsa3TobpsrgvzdD2zRm8rLCewRLj7kPYNj5Z0iqgFzeNt3iQBqWgyxnhvgNTYVSyItEGGCTfBW8V7qBFwUs6u7t5RYnf3FcKD9yRlIYsIuWzBoXEt0U5qPYmKDUjF3MhSfk5i461tJVCUlglsTOAYXBak36WrpK8079RDmBniKs3bGyqsuClWmw7QaVDu8q0
VitRah6RT5iDLaUsZ12pXWABjoh59H8xw64UxQV71TWnpsC2irRpJJzpSN0GPYrC8puBE1ULNMLQtTwVDeqmcDMQ3XS5RNfiXVCxWUVu4UvR0tmAhIp8CjaPQqQ7lfu2Um8cQ1D1B54dztP4D9Kzu8fPbOmcjaarafXPOUPaGleqi4hKOrOjuVsjAth4XiQHBk6lVs5CZIgHqRV2IChaCTziaTgvfojdcOkM8uNJDOIxkL8YJInXyqXQmxtn965
rP5WhyvmV2bAYNRQEdsLVdi3lYf1R43TqhbnFiwWCXKpZlyzvs6P0No5Mbn5PnV9cEOKl9qqFxcWUC4adS5bo4uNTurYIM3QYpDhKwFZujWa1GUi0vCJvQb9PaHRDrJYqInLythnT8vclPlh3ivOe0slTek5EyfWv0rNSImBlfRwmOaHl9q27tbKIZ8FGBXCZLSANJaQmKgI74uyUwRUxpq0ayfieLmTo7OluANqvTblnItx1uNigRg1lCV8BM3
AOVRTAOtuaPKD98mr45uGDZwHFP1I9ELiOOYo7tzcWBKkLCvkTACXvAUNO4VOZ8kKPZ7WxuWKVQkwHCsbpRbsYgwzqgnNgy5JZlSJWXxDM7FcEEhE0NCALK2CVVvtOMlG2Mg0Q7PPlN4Qr7Gjn1IYnixPm3YtfoMQHY5RT6maNgxMrrCofsPXYJKEhG3RYVRKyDhttJb8j2reyD4oiI4Ym0k7HpDEMknAUynch9m0MWf8NR0ANOILhvNhD1acWD我生成了一个255长度的目录,与4个255命名长度的文本文件,每个文本文件里面只有有限的几个字符。

实验证明,先打包的策略确实会优于直接压缩的策略。我们可以发现,长的文件目录与文件名只会影响打包文件与直接压缩文件的大小,总体来看,直接压缩的效率会无限趋同于打包的压缩效率。先打包策略则大大的提升了压缩效率。原因也十分的简单,虽然文件目录名字加长,会影响打包时核心目录与头文件中的数据冗余,但是在此进行压缩时,整个zip打包文件被作为了一个整体,数据冗余的部分也会得以压缩。综上所述,先打包在压缩的策略确实适用于多文件的压缩,可提升压缩效率。
由于这种机制的存在,后续可以尝试在zip文件里面实现一下隐写,看看这种比较反直觉的机制是否可以带来一些bit为的冗余。啊,挖个坑吧,如果后续有时间,有精力可以进行一下独立研究。









































































































全部评论 (暂无评论)
info 还没有任何评论,你来说两句呐!