
- home
首页
links
-
view_list分类keyboard_arrow_down
-
access_time归档keyboard_arrow_down
-
view_carousel页面keyboard_arrow_down
rss_feed
友人帐
RSS订阅
请注意,本文编写于 1405 天前,最后修改于 1405 天前,其中某些信息可能已经过时。
啊!这一晃十天过去了,好像上一次更新博客就在昨天!yysy,是不是因为懒所以没有更,而是因为。。。。好吧就是懒。这周和师傅们打了一个小比赛,第一道题目又是一道python字节流。这种题只要做过一次,之后就会轻松许多了,所以就没有必要在整理一遍了。之后的题目就是一些creakme,没什么有意思的地方。直到我遇到了这一道题目,我才有了更新的动力。这道题目很有意思,题目的名称就叫花代码,但是事实上和花代码的关系并不大。但是这是我第一次手工去花,还是有必要记录一下的。再有就是,当我分析完整个程序之后,我遇到了一个新问题,那就是base64在python3与python2里面的用法好像有点不太一样,这里要谢谢子洋师傅帮忙改的python脚本。这里真的就是python基础知识的不过关,卡了真的很久。强烈建议学校加入python的基础课(虽然加入了可能我也不会好好听)。不多说了,开始看看这道题目吧!
其实早在之前的Joker那道题目中,我就想系统的学习一下花代码了。但是很不巧的是,joker使用的是SMC技术,通过动态解密的方法影响静态分析。所以当时的花代码我只掌握了理论,并没有亲手进行实践。这道题正巧就是一道存在花代码的题目。首先要明确的是反汇编软件的工作方式,这个在《加密解密》里面有明确的讲解。反汇编软件的算法主要有两种,一种是线性扫描算法,一种是递归行进算法。线性扫描是一种计算含量很低的算法,主要实现原理是逐字翻译,先取一个字节,判断是否是指令,然后将对应的后几个字节翻译为数据,依次类推。所以花代码就可以很好的干扰这种分析算法,在一条指令后加入一个单独的数据,会导致反汇编认为这个是一个指令,从而导致之后所有的代码发生错位,导致反汇编无法正常进行。对于递归行进算法的软件,不会被这种简单的花代码误导,但是也有方法可以使其产生错误。在递归算法中有一个重要的假设:每一条控制转移指令都能确定后续的转移地址。所以只需要让其无法确定转移地址即可。这里不做过多的讨论,下次碰见之后再展开。
首先我们打开IDA,IDA是典型的线性扫描算法的反汇编软件。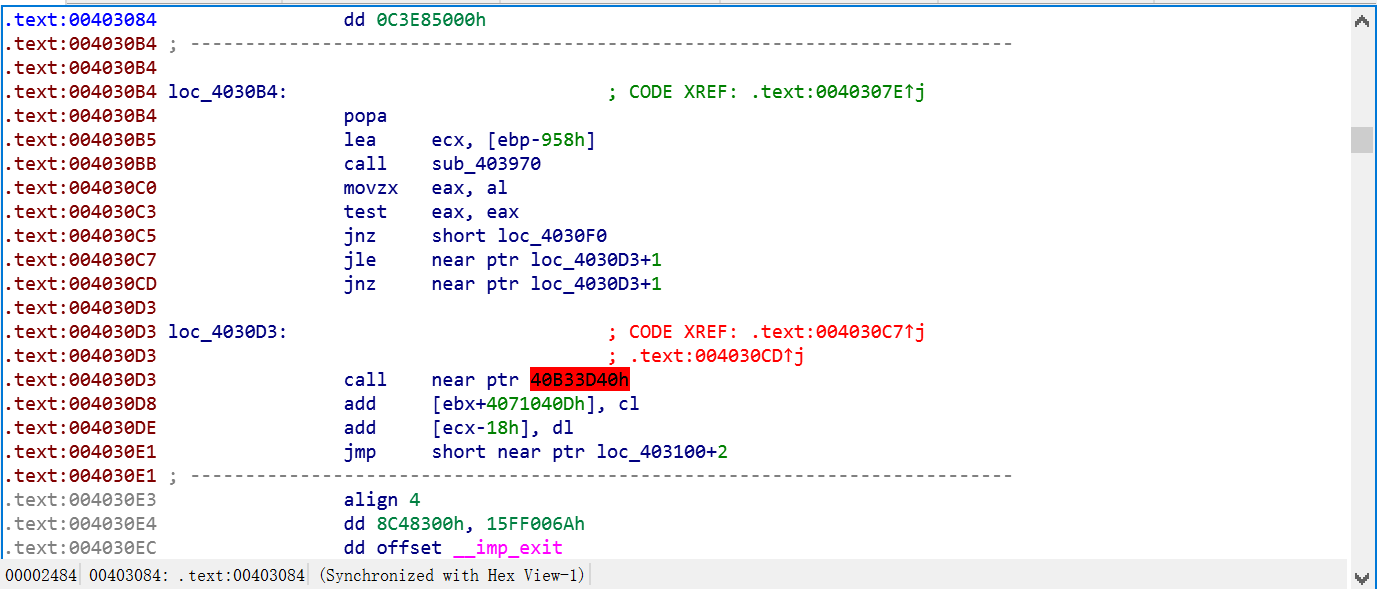
我们看见了一个大大的红色标记,并且在后面有很多没有被翻译成汇编的数据项。上方的两个跳转都指向了0x4030D3+1这个地址,但是很明显,0x4030D3+1这个是0x4030D3这个call函数数据的地址。这个就是最简单的花代码,由于加入的一字节的数据(数据所对应的汇编代码就是call指令),导致后续代码出现了问题。所以我们只需要把这个数据nop掉就好了。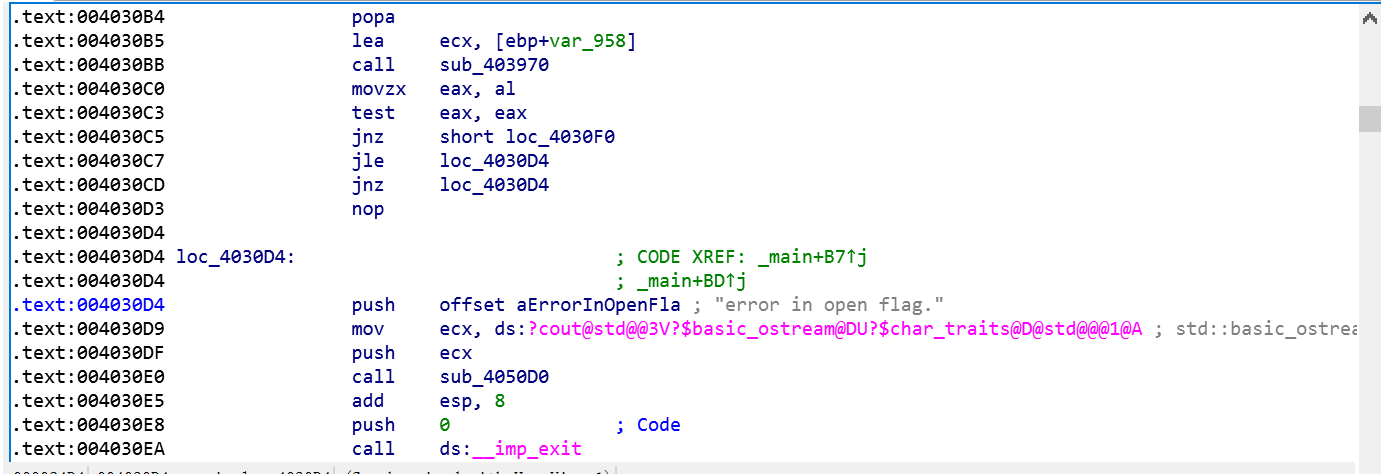
IDA还是蛮厉害的,我一开始以为我需要在将垃圾数据去掉之后,需要手动分析。在我将代码nop掉的一瞬间,IDA就完成了对后续代码的重构,直至遇见下一个花代码。将这些花代码都处理掉之后,我们要重构main函数,由于一开始分析失败,这里并没有一个主体函数,导致我们无法F5。创建函数。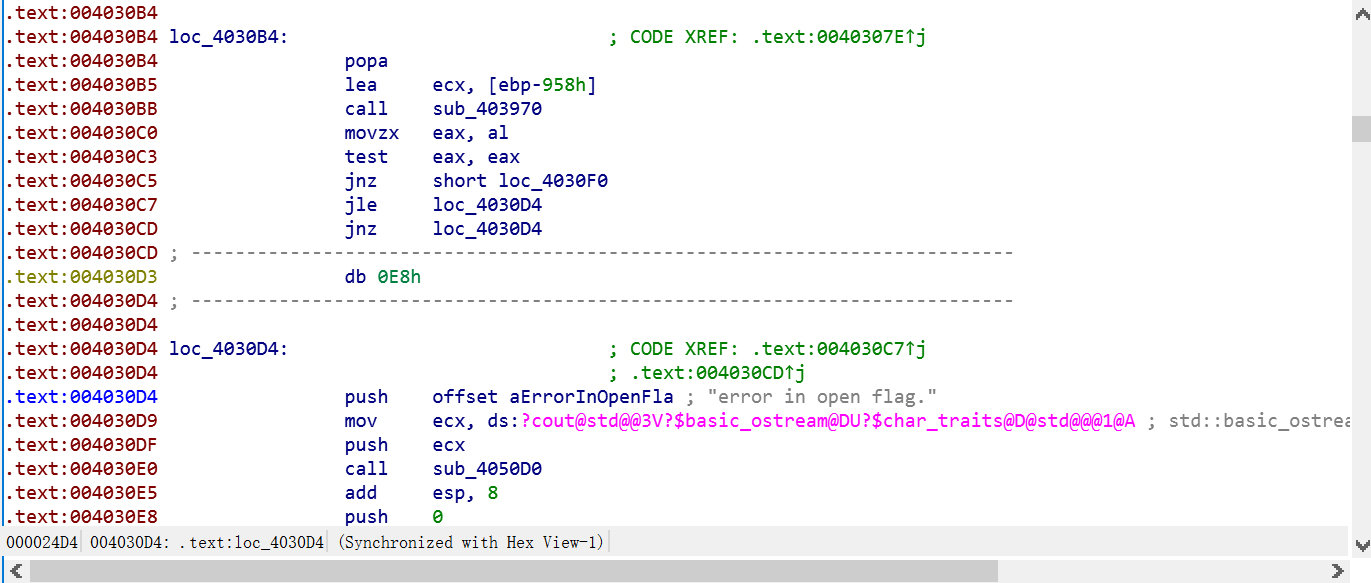
最后F5,nice,只要做过C++的逆向的同学们肯定都不会忘记被C++支配的恐惧。F5的函数完全不是给人看的,这是一个C++写的程序,F5的伪代码要多恶心有多恶心。啊这,只能选择OD了,但是手工去花的过程还是蛮有趣的(虽然对这道题目没啥影响)。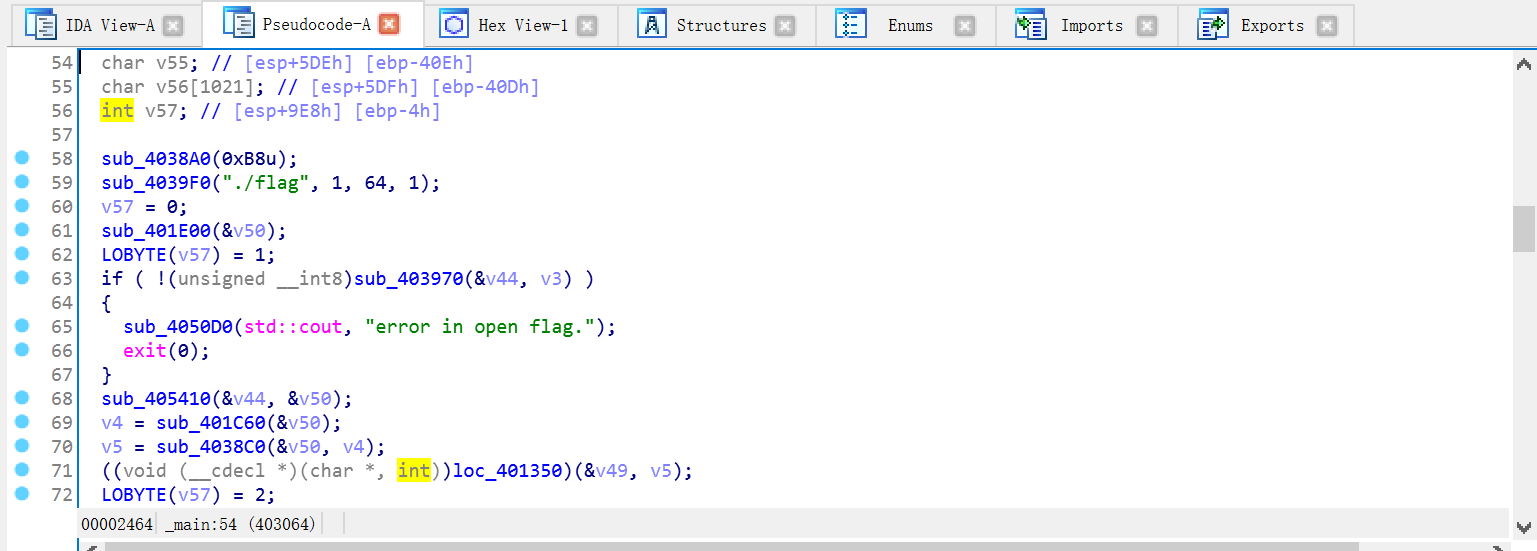
OD稍微的比IDA聪明一点,原因是OD自带两种算法,打开程序默认的是线性扫描算法,我们只需要ctrl+A就可以启动递归算法。然后我们就成功的过滤掉了花代码。
首先程序会打开名为flag的文件flag.txt不太行(可能是因为我开着后缀的原因吧),如果没有就退出程序并且报错。我们建立flag文件,输入12345678901234567890(这个地方有一个小细节,尽量4的倍数,原因很简单,就是当牵扯到base64的时候,可能会导致没有“==”,没法让我们一下反应过来,这是一个小教训)。首先程序对输入进行了base64。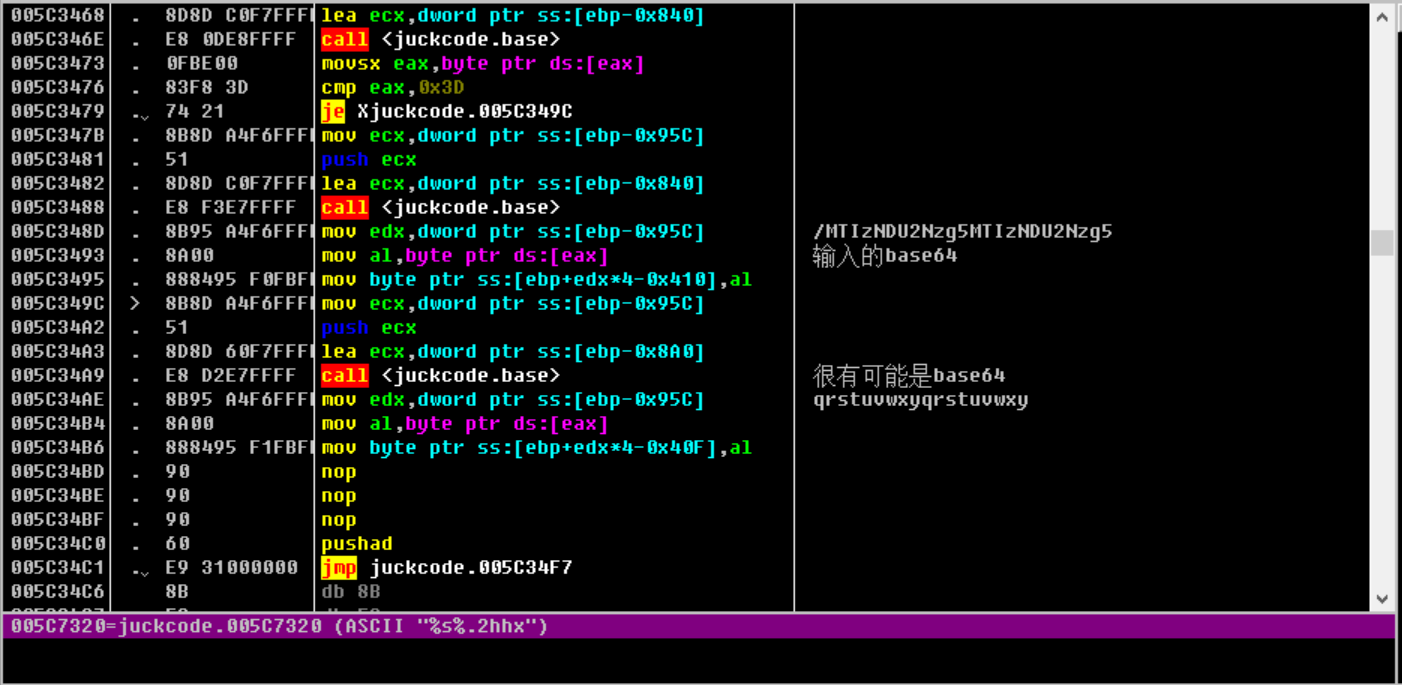
然后对输入进行了三次不同的操作,分别是+0×40、<<7和-0x9e,然后对操作完的字符串进行base64.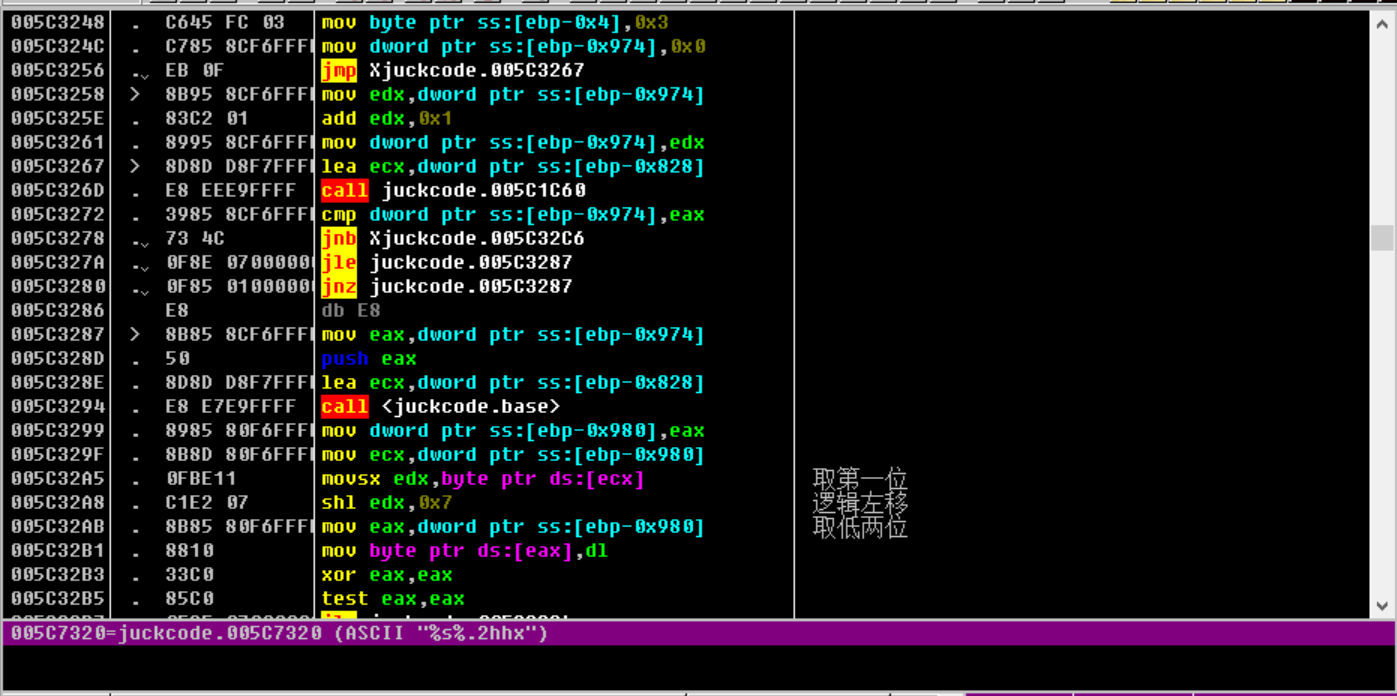
最后将四个字符串进行拼接,大概是A1[0]+A2[0]+A3[0]+A4[0]+A1[1]+........
之后将每一位的字符转化为十六进制再将左右拆开,比如0x11-->0x31 0x31,最后在按位+16输出。
整个函数没有检验函数,全靠输出与题目所给的字符串进行比较。加密逻辑虽然没用到很复杂的密码学,但是程序十分的繁琐,由于我是纯动调分析,所以花费了蛮多的时间的。动调的时候注意栈与寄存器,对产生的字符串要敏感。本身以为这到题目就结束了,但是噩梦才刚刚开始。
这里就是牵扯到了python的基础知识,首先base64模块的加解密需要bytes的数据,但是bytes模块我又用的不太好,所以在逆向脚本上墨迹了好久。再次感谢子洋师傅帮忙改的脚本,先上脚本:
import base64
s = 'FFIF@@IqqIH@sGBBsBHFAHH@FFIuB@tvrrHHrFuBD@qqqHH@GFtuB@EIqrHHCDuBsBqurHH@EuGuB@trqrHHCDuBsBruvHH@FFIF@@AHqrHHEEFBsBGtvHH@FBHuB@trqrHHADFBD@rquHH@FurF@@IqqrHHvGuBD@tCDHH@EuGuB@tvrrHHCDuBD@tCDHH@FuruB@tvrIH@@DBBsBGtvHH@GquuB@EIqrHHvGuBsBtGEHH@EuGuB@tvrIH@BDqBsBIFEHH@GFtF@@IqqrHHEEFBD@srBHH@GBsuB@trqrHHIFFBD@rquHH@FFIuB@tvrrHHtCDB@@'
a = ''
for i in s:
a+=chr(ord(i)-16)
#print(a)
print(a)
import struct
S2=b''
for i in range(int(len(a)//2)):
#print(a[i*2:i*2+2])
#S2+=bytes(int(a[i*2:i*2+2],16))
S2 += struct.pack('B', int(a[i*2:i*2+2],16))
print(S2)
s3 = str(base64.b64encode(S2))[2:-1]
print(s3)
s4 = b''
for i in range(len(s3)//4):
s4 += struct.pack('B', ord(s3[4*i]))
print(s4)
l = len(s4)
if l % 3 == 2:
s4 += b'='
elif l % 3 == 1:
s4 += b'=='
print(base64.b64decode(s4))这里用到了struct模块,下面会详细的说,这里要记录一个bytes的用法。现在来想一下,就是bytes(95)到底是什么?是b‘0x5f’吗?不多说了,看这里:
class bytes([source[, encoding[, errors]]])
如果 source 为整数,则返回一个长度为 source 的初始化数组;
如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
如果没有输入任何参数,默认就是初始化数组为0个元素
import struct
buf1=259000
bin_buf1=struct.pack('i',buf1)#3f3b8
ret1=struct.unpack('i',bin_buf1)
print(bin_buf1)
print(ret1)输出结果:
b'\xb8\xf3\x03\x00'
(259000,)由于字节流编码这里我一直不是很清楚,所以这里还是稍微解释一下。这里的字节流是十六进制的,但是是小端序的,就是一开始的字符在最头头。比如这个例子,十六进制是0x3f3b8,字节流是b'xb8xf3x03x00'一样。
buf2=3.1415
bin_buf2=struct.pack('d',buf2)
ret2=struct.unpack('d',bin_buf2)
print(bin_buf2)
print(ret2)输出结果:
b'o\x12\x83\xc0\xca!\t@'
(3.1415,)啊这!我现在好像不太明白这个转化原理,等明白了会补上。
buf3="Hello World"
bin_buf3=struct.pack('11s',buf3.encode())
print(bin_buf3)
ret3=struct.unpack('11s',bin_buf3)
print(type(ret3))
for i in ret3:
print(i)
输出结果:
b'Hello World'
<class 'tuple'>
b'Hello World'
这个地方值得注意的一点是,所有的解包操作后,生成的是一个大小为1的元组。这个元组可以直接用str转化为字符串,但是相比较开始的字符串而言会多出来b‘’。
# 按照给定的格式化字符串,把数据封装成字符串(实际上是类似于c结构体的字节流)
string = struct.pack(fmt, v1, v2, ...)
# 按照给定的格式(fmt)解析字节流string,返回解析出来的tuple
tuple = unpack(fmt, string)
# 计算给定的格式(fmt)占用多少字节的内存
offset = calcsize(fmt) 最后将表贴出来方便之后查阅。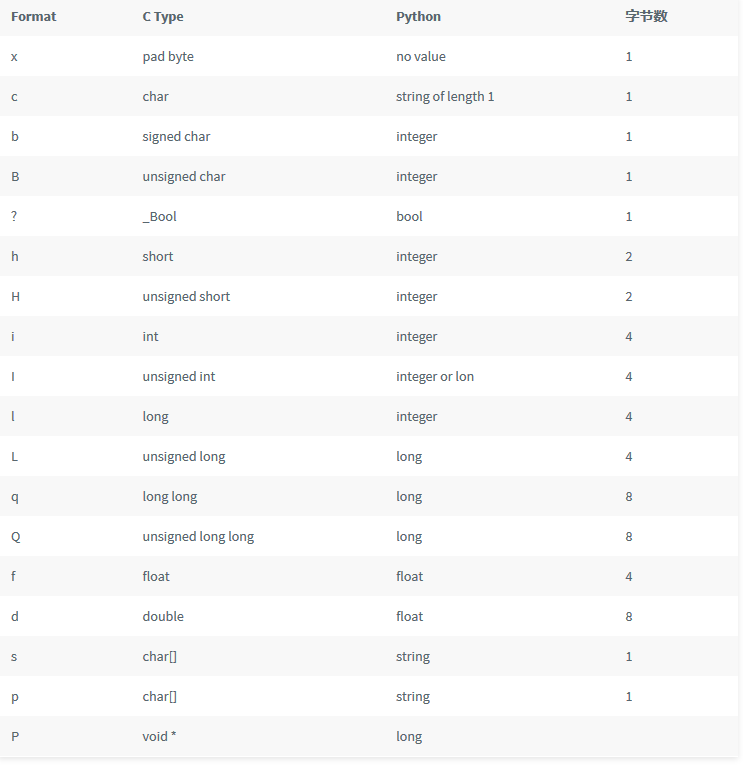
本次主要是两个知识点,一个就是手动去花的实现,另一个就是python字节流的struct的实现方法,这玩意比bytes感觉要靠谱一点。以后多加练习,最后就是,一道阴间题目bts,这道题目我没有找到wp,并且IDA无法正常打开,在师傅们的讨论下,可能是因为IDA不支持。解决方法很简单,就是去找这种指令集的字节码含义,完成自己手动的反汇编。我试试把,但可能试试就逝世了!









































































































全部评论 (暂无评论)
info 还没有任何评论,你来说两句呐!